We all have too many papers to read; in the past I have just dumped a bunch of related papers together with some light summary, to say why they’re interesting. This paper roundup is on evaluation and benchmarking, which has been a theme for me lately.
Benchmarking robotics is hard; collecting robotics datasets you can actually use is hard. This blog post is a short overview of a few datasets that might be of interest, both lesser-known ones that struck me as interesting and a few large and well-known ones for context.
You can also use this blog post to scroll through and see what the datasets people are talking about in a RoboPapers episode, actually look like.
If you like reading thoughts on robotics, please consider subscribing. Usually I write more in-depth summaries; this particular blog post is much more minimal and “stream of consciousness” than usual.
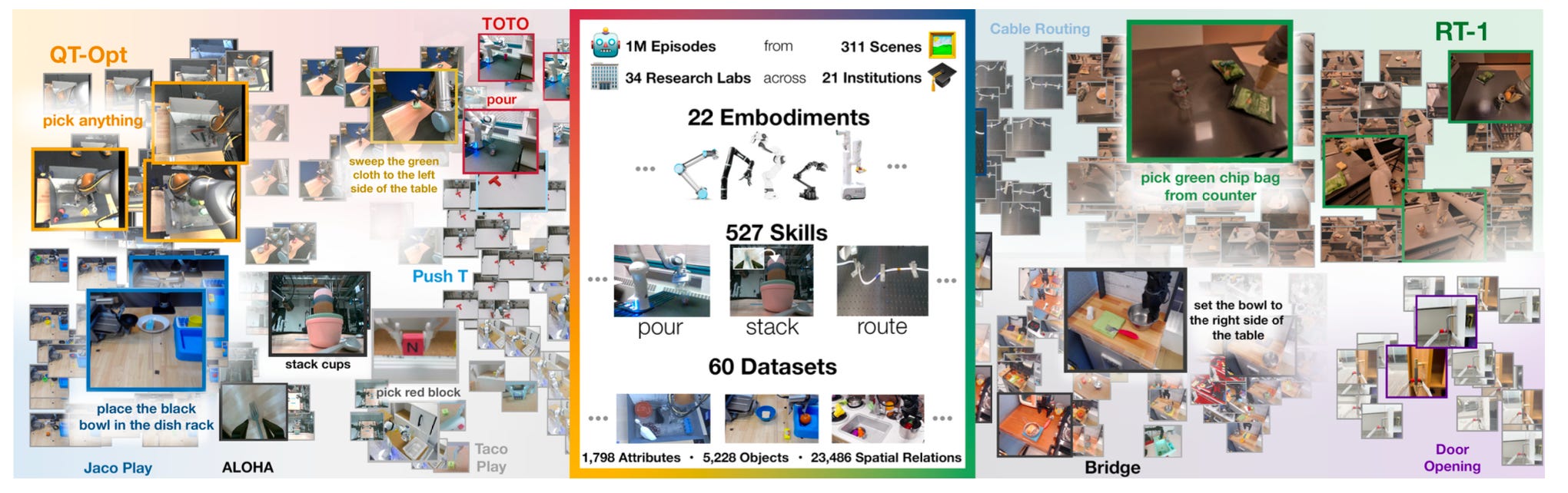
An absolutely huge dataset of robotics data. At the time of initial publishing, it had more than 500 skills and 150,000 tasks included, with a wide variety of robot embodiments. It won the ICRA 2024 best paper, and has about half a million authors. Find it here.
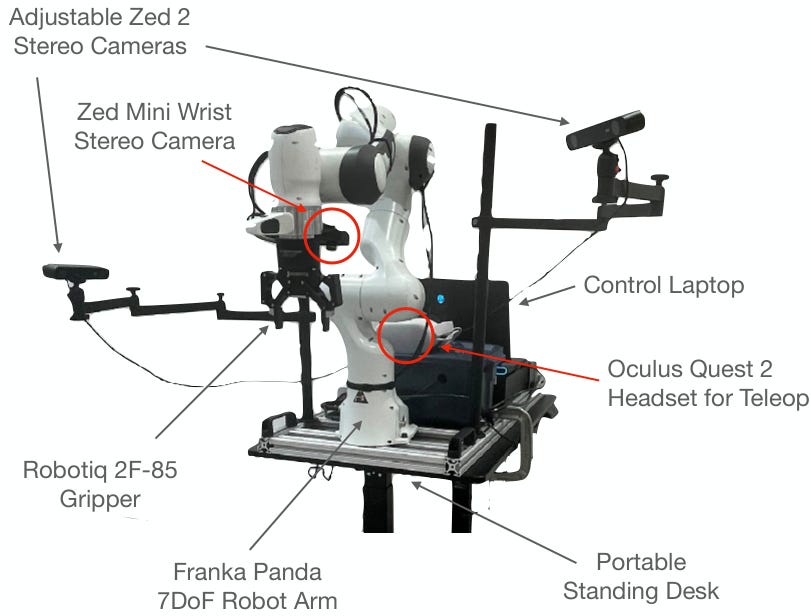
An important subset of Open X Embodiment, and a dataset that’s still heavily used today. Partly because the hardware setup (above) was duplicated across so many universities. Contains a mix of office, kitchen, and home environments, with a Franka Panda arm and a zed camera on the wrist, plus a number of third-person views.
Check out the website for more.
The Build team has released 10,000 hours of video data. 192,900 monocular wide-angle egocentric video clips, collected by human workers in a variety of different environments.

You can find the data here on HuggingFace. And look at Eddy Xu’s X thread.

600+ environments with 120 million frames. Task, language, and 3D hand pose annotations. Often these datasets do not have annotations, so this part is potentially really valuable.
Check out the original X thread from Ahad Jawaid. Github site for OpenEgo.

A task planning dataset, with complex multi-step tasks and question answering. You can find it on HuggingFace here.
A large interesting dataset of human-object interactions. Not sure how useful it is, but given how much object interaction in whole-body robot control has accelerated recently, this seems worth a look. You can check it out here.

You probably know this one; it’s one of the biggest.
With 130 tasks spread out across 4 task suites, it has a lot of variety, and has been used in a ton of research papers so far. The code is also open source.
Contains datasets with RGB information from wrist cameras, proprioception data, language, and PDDL scene descriptions here. These are all high-quality human teleop data, making this benchmark highly suited for learning-from-demonstration research.
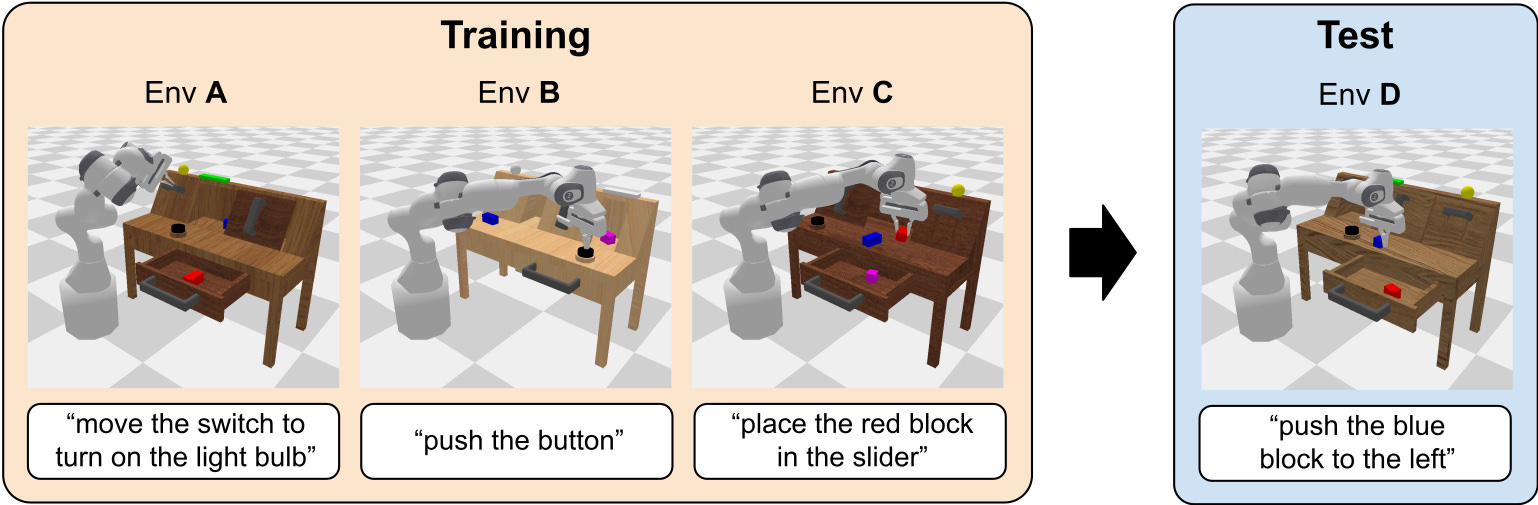
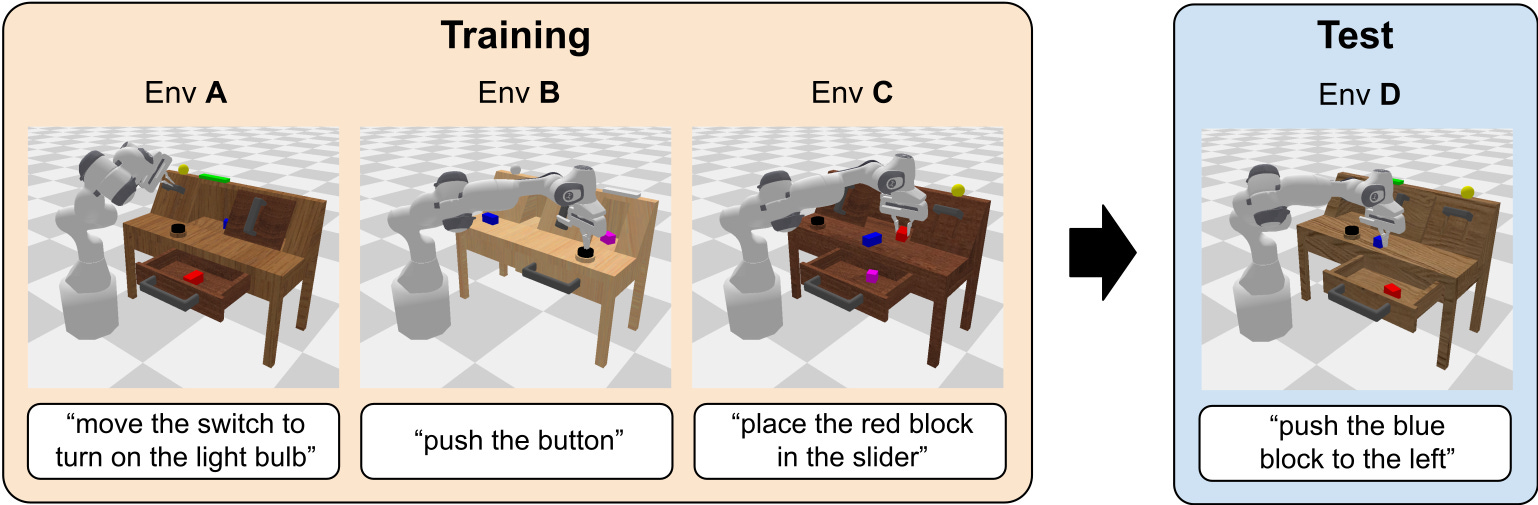
A commonly-used benchmark by Oier Mees for language-conditioned task execution. It uses the Franka Panda robot and has a simple setup with some light variation in objects and coloration, together with a good variety in pick and place tasks. Find it on Github here.
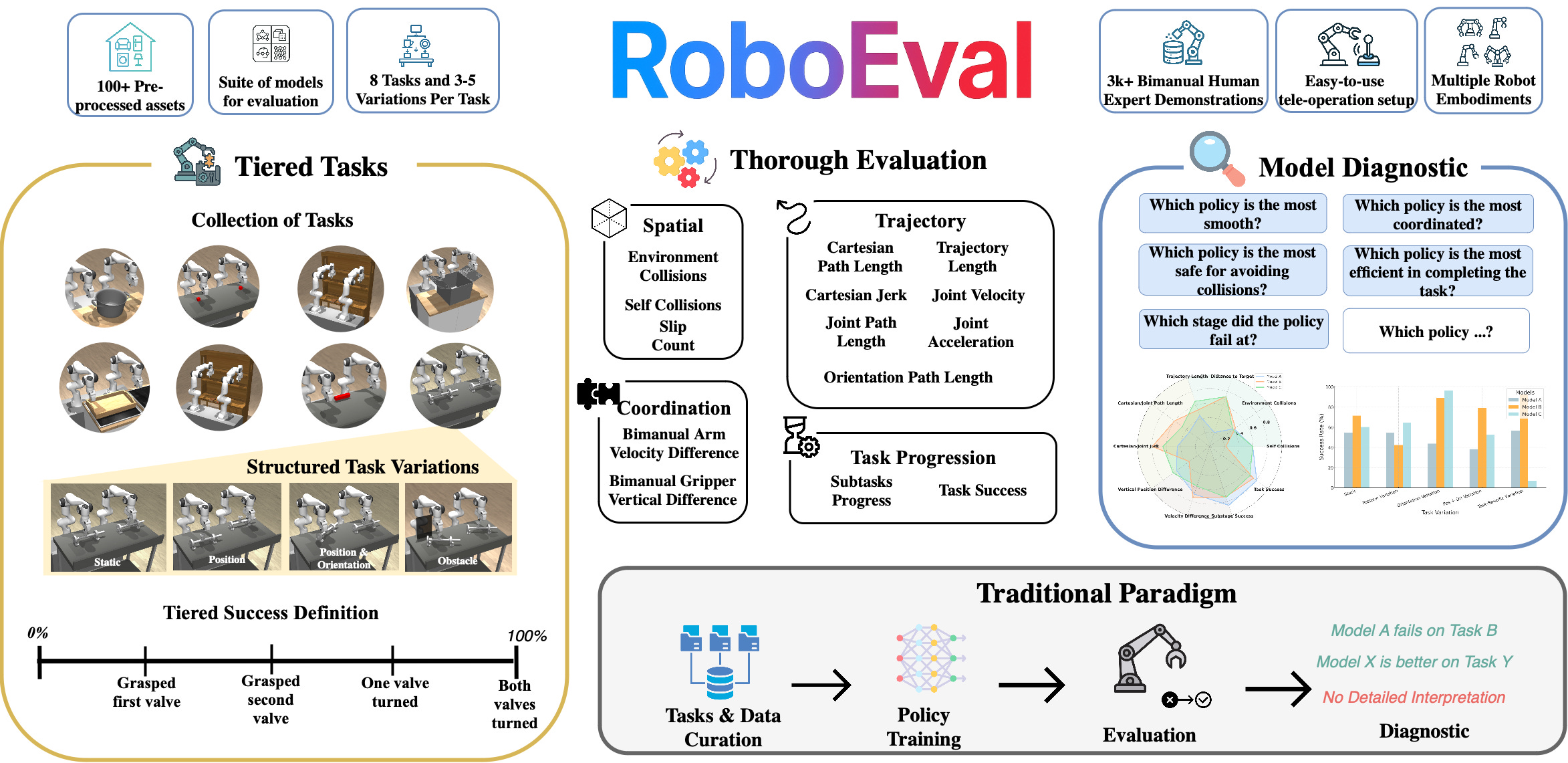
A benchmark of 10 base tasks and 3000+ demonstrations which aims, somewhat uniquely, to provide unique, non-binary metrics of performance, in order to give an idea of how and why experiments are failing: there are trajectory smoothness metrics, it tracks environment collisions, etc.
Check it out here. Thread with thoughts; original X thread.

Real-world benchmarking via web socket to your policy. Grad students run evaluations in different university setups.
I’ve written about this one before, when writing about evaluations. I think it’s one of the best ideas for policy evaluation I’ve seen; though it’s still woefully limited in many ways.
See the X thread here, or check out the project site.

A benchmark specifically aimed at sim-to-real correlation. Scan an environment with your phone, use Gaussian splatting to construct a scene, and use a set of tools to create a photorealistic simulation. Ships with a set of “real-to-sim” environments in which performance correlation with the real world was validated.
Check it out here. Robopapers episode.

A benchmark specifically aiming to close the sim-to-real gap. Sedlacek et al. put together this benchmark designed to be a good simulation that closely represents the real world. See the post on this from Evangelos Kazakos on BlueSky.
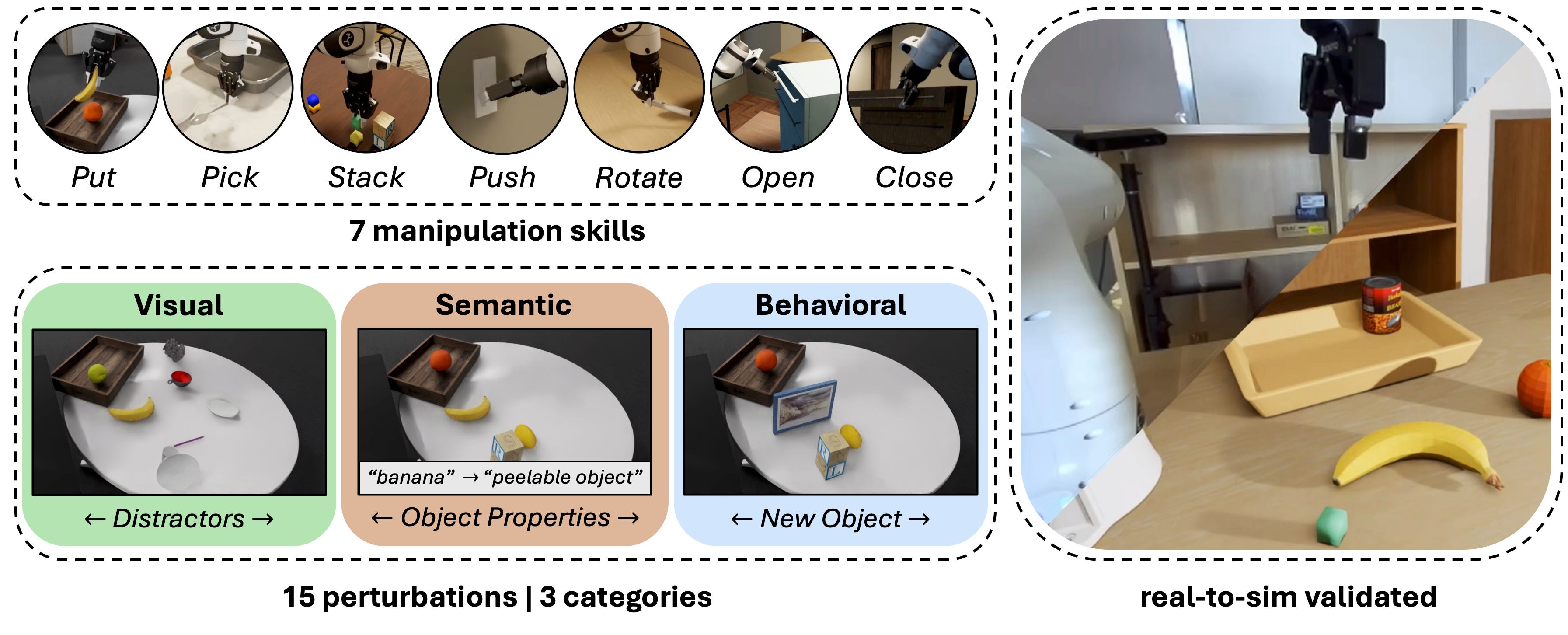

A video understanding benchmark - but of course video understanding is very closely related to robotics. Basically, how well can video models understand certain physical problems?
Check out the website and the thread on X. There was also an ICCV 25 challenge and associated workshop.
There are a lot of benchmarks and datasets out there; comparatively few (1) have gotten real uptake, and (2) show some actual correlation with real-world results. This is still an active area, and I personally am very excited about potential for real-world benchmarking like RoboArena (though it’s very expensive).
Ultimately the best benchmark is the real world — fortunately, with common platforms like the Unitree G1, we can expect people to open-source code that others can immediately use and deploy.

Sometimes, you need to raise a round for your robotics startup and the training run just didn’t go so well. Or maybe the CoRL deadline is a week away and the results just aren’t there. Never fear; you have options. Follow this guide and everything will work out just fine.
Let’s discuss how to make your model look as good as possible.
Don’t let other people run comparisons. Remember what happened with Llama 4: if other people can try your model out, they’ll quickly uncover its limitations. If you can keep your model secret, that’s best.
Control the environment of your demo carefully. Lighting, objects, initial robot configuration, and so on. This lets you overfit the demo scene and get really nice, smooth, high quality motions.
Never show your failures. This one might seem obvious — why would I show failures? — but if people can see where your model fails, they can start to see the limits of what you can do. Only strong robotics papers and results can show failures with confidence.
If you have to let other people run comparisons, choose the people carefully. Make sure they’re only happening in the right circumstances, ones your model supports as roughly in distribution. Absolutely don’t do what Physical Intelligence or NVIDIA do and open source your model so anyone can benchmark it.
When working on the results section of your research paper or blog post, you may be tempted to include some baselines. This is a good idea; just be careful to choose weak baselines so you look good. Octo is a great choice here; it was well publicized but had lots of limitations that weren’t widely discussed.
On the same note: cherry-pick your benchmarks. There are a ton of robotics benchmarks out there, and they all test subtly different things. Importantly, these differences are not obvious to people who are not familiar with the benchmarks involved.
Now, you may be thinking: “Chris, this is all great advice; but people will call me out if I follow these rules.” Don’t worry about that. There are so many little things which influence robotics performance: camera placement, arm configuration, object diversity, low-level controller implementation, and so on.
As long as you can make an argument your setup has to be slightly different from everyone else’s, you can get away with a lot. For example; a benchmark I like is RLBench, which turns out to be a very difficult one for many VLAs, and many successful methods on this benchmark instead use motion planning together with a higher-level goal prediction model.
Second, as a result of the above, robotics benchmarking standards are quite low relative to other areas of machine learning. Papers from very famous roboticists get away with these things all the time, and they’re under much more scrutiny than you are. You’ll be fine.
Open source code and models. Not always possible, but always welcome.
Very diverse scenes and environments. Modern robotics learning methods are very, very good at overfitting to a small task distribution — a clean table, objects at most a few centimeters from where they started.
Don’t be afraid to show failures. We all know robotics methods fail a lot; showing these is a strong signal, and also helps qualify where it works and where it doesn’t.
Compare against the current best methods. Pick the best models head-to-head with embodiments and benchmarks they report on. Don’t cherry-pick.
On the same note, I think paper reviewers must be accepting of some results which aren’t as good as other methods; it must be allowable to fail at some benchmarks, or people will cherry-pick.
Almost all of the robotics videos and results you see are, I believe, real — in that they’re doing exactly what the creators say they are. The problem is that because it’s so easy to overfit to a particular scene, and because the limitations of a model are so hard to ascertain from a 30 second clip, it’s really hard to tell whether a team is making progress toward the underlying goal of general-purpose embodied intelligence.
And robotics is hard; just because a team is employing some of the tricks I wrote here does not mean their results are invalid or their model is weak. I am certainly guilty of them all, at one time or another! One of the fundamental issues with robotics projects is that there are so many things that influence performance, that it’s very hard to distinguish the signal from the noise.
On the same note: lots of machine learning researchers from other fields don’t understand how hard robotics benchmarking is. They will often insist on building their own, usually simulated, benchmarks, which invariably don’t tell us anything and just add more options for #6.
In the end, robotics benchmarking will be solved by having lots and lots of robots, and models that actually work across most of them. More projects like Lingbot-VLA, DreamZero, and pi-0.5 — models that people can actually try out on different robots, use, and openly compare.
I wrote about evaluation a bit in the past, and will surely do so again:
]]>
The release of the Imagenet dataset was a landmark moment for the nascent field of deep learning. This collection of what is now 14,197,122 images covering more than 100,000 concepts (“synonym sets” or synsets) was key in driving and assessing early progress in deep learning, in part because it signaled the ongoing shift from “better algorithms” to “better data,” which in turn unlocked much stronger algorithms. Quintessential, landmark deep learning papers like Resnet and ViT were evaluated on ImageNet.
The dataset has many nice qualities: compared to other popular vision datasets like CIFAR-100, ImageNet has much more variety; it has high-resolution images; a method working on ImageNet tells you something (not everything, but something!) about whether it will work in the real world. But it’s still manageable: most “Imagenet” results stem from Imagenet-1k, a clean subset of 1,000 chosen object classes (“Golden Retriever”, “Sofa”, et cetera).
But this was a very, very controlled problem: image classification; i.e. “which of these 100,000 classes does this image that I am looking at belong to?” Image classification is easy: the problem is clean, it’s well defined, it’s not going to change or fluctuate. It is, in short, it fails to characterize systems which operate via repeated interaction with their environment as opposed to a one-off image capture.
And so we come to robotics. With the rise of humanoid robots and massive funding for real-world robotics research, it’s more important than ever to be able to tell what actually works and what does not — but at the same time, this is more obfuscated than ever.
Fundamentally, though, there are two main options: evaluate in the real world (somehow!) or evaluate in a simulation. Each have serious advantages and disadvantages. Let’s talk about them.
If you’re interested in seeing more of this kind of post, please like and subscribe.
First, though, let’s discuss the issues with using an offline dataset for evaluating robot trajectories. It works for images and language, after all — why shouldn’t it work here?
An offline dataset might take the form: Predict action given current state observation and task description. However, robotics is an inherently interactive domain; small errors in action prediction accumulate over time, and lead to different outcomes. Good policies compensate for these, and recover from partial task failures.
Without an interactive environment to evaluate in, we can’t compute task success rates, and we can’t determine whether a policy would be useful at deployment time. This leaves us with two options: (1) test in an interactive simulation, and (2) find a way to compare methods on real hardware.
If we need interactivity, perhaps the best benchmark, then, will be in simulation. And simulations are getting more powerful, more interesting, and more diverse all the time. More importantly, we’re regularly seeing previously-impossible examples of sim-to-real transfer. See, for example, Doorman, by NVIDIA, which was sufficient to teach a robot to open a door — though note many difficulties involved in this work!
Simulations are getting more powerful and easier to use all the time. But few of these simulations rise to the level of a usable benchmark, i.e. something like Chatbot Arena, Humanity’s Last Exam, or SWE-Bench Verified.
For robotics manipulation, two of the most notable benchmarks are Libero and Calvin. These implement a wide range of tasks with language conditioning (“push the button", “stack the blocks”), which means they can be used to train and evaluate multi-task policies. For mobile robotics tasks, the most notable simulation benchmark is Behavior 1k, which implements a thousand challenging simulated household tasks.

But there are many more, and they all have subtleties which impact which methods work. This makes it easy to “choose your own” subset of benchmarks upon which your model will perform the best, which renders moot the whole point of even having benchmarks in the first place! Efforts have been made to unify all of these different simulators, like Roboverse.
Another issue is that authoring tasks in simulation is hard. In the real world, if I want to have the robot stack blocks, I go buy some blocks and drop them in front of the robot. In a simulator, I need to get the friction parameters right, masses, make sure contact is working properly, et cetera. I need to implement cost functions (for RL) and success criteria, and this only gets harder as I start to scale simulation up. One notable effort to reduce this pain point is the Genesis simulator, which attempts to use user-prompted natural language to help create environments.
Fundamentally, though, simulations are still hard to work with and an inaccurate representation of the true robotics problem, without sensor and actuator noise, with overly-clean problems, and with unpredictable, often-inaccurate contact dynamics. As a result, there will always be a role for real-world evaluation.
Obviously, comparing performance on a real-world task for robots is the benchmark. But running any kind of evaluation in the real world for robots is hard. In simulation, you don’t need to “reset the environment,” putting everything back where it was before you run again — something I have done many times in my life as a robotics researcher. Fortunately, we’ve seen a couple ways in which this problem might be addressed, especially inspired by recent work in large language models.
When the AI field moved towards large language models, we quickly saw a rapid proliferation in the number of benchmarks of ever-increasing difficulty - benchmarks like Humanity’s Last Exam fit the Imagenet mold of: here is a dataset, see if you can get the right answer.
But benchmarks quickly saturate; and they never solve the “real” repeated-interaction, high-dimensional data problem we actually care about, whether the goal is language or a robot. One evaluation method which exploded as a result was Chatbot Arena: a platform in which a user comes up with their own prompt, it is sent to two different LLMs, and the user chooses whichever response was better. While the particular implementation has not been without issues or critics (especially notable is Llama 4’s apparent benchmark-maxxing), the approach is scalable, in that it doesn’t require running a full sweep of all possible queries every time. While it’s not perfect, because no two evaluations are the same, it gives you an ELO rating which gives an idea how competitive every model is with other options out there.
This is a great fit for robotics, where similarly, running individual evaluations tend to be extremely expensive. Tournament-style evaluation most useful because it minimizes the number of expensive evaluations you need to run in order to see if it works; crowdsourcing queries also helps prevent overfitting to the benchmark (which was a perennial problem in a lot of computer vision research, and persists in many fields to this day).
Examples include RoboArena, which is a community-run cloud service for evaluating robot policies. Your policy gets executed on the cloud, and you just need to provide a service exposing it. This does limit the kinds of tasks that can be evaluated, though: latency will always be a serious issue.
The authors of the large humanoid robot dataset Humanoid Everyday are also planning a cloud service for evaluating robot policies on a real Unitree G1 humanoid; you can check their site for details (as of writing, it still says it’s coming soon) and watch our RoboPapers episode on Humanoid Everyday to learn more. You can also watch a podcast episode on RoboArena while you’re at it!
All this is very limiting, though. Maybe we should just expect that people will just own robots upon which standard policies are expected to work, so that they can do their own evaluations on their own problems.
It might even be possible for something open source to take over, something that I’ve written about in the past. The HuggingFace SO-100 arms have seen some significant uptake in the hobbyist community, though very few have made their way into academic research papers that I’ve seen. We might see mobile versions of such a platform succeed; XLeRobot, for example allows for you to, at a fairly low cost, test out different mobile manipulation policies.

Of particular note today is the Galaxea R1. This platform is available for a relatively low cost, and comes in several varieties to support easy data collection, like the R1 Lite. The R1 Pro was used in the Stanford Behavior Challenge at Neurips 2025. You can download a VLA and associated pre-training data for it. It was even used in the recent RobbyAnt LingVLA, which used 20,000 hours of real-robot data.
The most common platforms right now are probably the Trossen ALOHA arms, the YAM arms from I2RT, and of course the Unitree G1. It’s notable how compared to previous systems — available even 2-3 years ago — all of these robots are spectacularly cheap. Robotics has become substantially more affordable, and robotics research more accessible. As a result, maybe the best way of telling which methods are “good” is just to watch to see which methods people build off of when performing experiments with these common platforms.
So let’s recap:
Offline datasets do not work because robots never do exactly the same thing, these errors compound, and all robot tasks are too multimodal for this to be meaningful
Simulations exist and are useful, but are niche, hard to implement, and often missing critical aspects of the real world (usually visual diversity, implementation of interesting/relevant tasks, and high-quality contact simulation)
Real-world evaluation is slow and horribly expensive to run, and can’t match the expectations of other AI fields like language or image understanding in terms of speed.
This sounds dire, and it actually gets somewhat worse; because all of this has focused on assessing algorithms, and robots are not merely algorithms: they’re hardware plus an algorithm. Hardware factors — joint positions, sensor placement, motor types, backlash, heat buildup, and more — often matter more to task execution than the algorithm you’re using.
So any “real” benchmark comparison of, say, Figure 03 vs. Tesla Optimus vs. 1x NEO would by necessity look more like a human competition, where participants, say, go to a test kitchen and see who can load a dishwasher the fastest.
We’ve seen the early evidence of such events, like the World Humanoid Games, or the many competitions we see every year at major robotics conferences like IROS and ICRA. These are likely to expand, although major companies right now have too much to lose and too little to gain to bother competing.
On the model side, the fact that you can just download and run pi-0.5 on your hardware, for example, is an incredibly promising start. In the end, though, the answer to the question, “how do we quantify progress in robotics?” has to be “all of the above.”
]]>
Compared to other humanoid robots like Figure 03 or 1x NEO, Atlas is an alien. The product version of the storied humanoid robot from Boston Dynamics has strange-looking, bowed legs; it has an odd, circular head like a lamp, and all its joints can rotate all the way around.
If you want an illustration of just how strange this looks, watch this video from user CIX on X, recorded at CES 2026 in Las Vegas:
Contrast this with a humanoid like the Figure 03, which was clearly designed to mimic the appearance and capabilities of a biological human, something that I’ve covered before in a previous blog post.
Both of these robots are incredible pieces of hardware, but we must ask, why should Figure’s robot look so human while Boston Dynamics opts for such a strange form factor? Is it just a gimmick that Atlas can turn all the way around? If we’re moving away from the human form, why not just go all the way and make a robot that’s fully optimized for its task like the Dexterity Mech (video from Dexterity):
They do, on occasion, call this beast an “industrial superhumanoid,” and it’s a dedicated pick-and-place monster with a 60kg payload.
So let’s talk about why some of these robots look more or less human than others, and what the pluses and minuses are, with a particular focus on the new design from Boston Dynamics.

When asking why use a humanoid at all, the real question you’re asking is usually “why legs?” And this is an important question; lots of the robots, including the Dexterity Mech shown above, do not need legs. What are legs for, then?
Well, legs allow robots to:
Handle more complex and challenging terrain
Carry heavy things without requiring a large base
The first benefit is obvious — legs allow your robot to climb stairs or cross a debris-strewn landscape. They mean that your robot can be deployed in a wide variety of environments with far less concern about “preparing” the environment for robots.
This, however, rarely going to be a deal-breaker for real-world deployments, as it’s already economical to design industrial spaces to optimize productivity. Amazon, for instance, famously developed new techniques for creating flatter floors in its warehouses to benefit its Drive robots. So, in a real, large-scale deployment, legs are of use for handling terrain — but that’s only a very limited use.
More important is that legs allow robots to be smaller while performing the same tasks. Or, more accurately, it’s because a bipedal robot can perform the same work in a smaller, more constrained area. Because they’re dynamically stable and omnidirectional, an industrial humanoid robot like Atlas can carry a heavy load with a much smaller footprint than a robot like the Dexterity Mech.
This is important because in a factory or warehouse, you’re often trying to fit as much stuff into available space as possible — you don’t necessarily want all the extra space it needs to make a large, high-payload wheeled robot work.
But notably, this does not mean that your humanoid has to look human.

The new Atlas robot has a couple unique design features, courtesy of product lead Mario Bollini on X:
And the unique legs:
With only two unique actuators, the supply chain and cost of the robot can be greatly reduced versus a more human-like design. The fact that the legs can bend forwards or backwards gives it some more flexibility, but also means that the legs are swappable left to right.
And with that in mind, let’s go back to that first video by CIX, where the (prototype, not mass production) Atlas reverses itself during a procedure. Remember when I said the main advantage of a humanoid was working in a more constrained space? This design grants the robot distinct advantages in constrained environments.
Contrast this with the approach taken by competing American humanoid manufacturers like Figure, 1X, or Tesla. Their robots are very closely designed to match the human form factor.
There are a few advantages to this:
Teleoperation is easier. Even if your robot is superhuman, the humans operating it are not — and teleoperation is already pretty hard work!
We have lots of human data already. The internet is filled with human video data; training from this data, as 1X has done, allows you to easily resolve the robot data gap.
Our tools and technologies are all designed to be used by humans. This is a favorite argument of Elon Musk, for example. If your robot is expected to use tools or drive a forklift, you might want it to look human.
It looks and acts human, and people like that. Robots that work around people need to be pleasant and likeable; people might not want to purchase these strange, scary alien beings whose heads can rotate 360 degrees.
There’s a safety angle to this final point as well; if a robot’s capabilities are roughly human, people know what to expect from it, and it’s important humans have a good model of what robots can do if they’re going to be working and living alongside them. This is a huge part of the justification for the design of the 1X NEO, which has very humanlike lifting strength and capabilities.
Personally, I find that there are a lot of holes in these arguments.
I don’t buy that, in the future, we’ll want humanoid robots to use tools built for humans. When transportation in human cities switched from being dominated by horses to dominated by cars, every piece of our infrastructure changed. This will happen with robotics, too, as robots supplant human labor.
It seems very unlikely to me, for example, that humans will be buying non-robotic forklifts for their warehouses in 10 years. Every forklift will be something like a Third Wave robot; you certainly won’t be asking Optimus to go and drive a forklift, because the extra sensors necessary for automation will be extremely cheap.
The same will go for tools; maybe robots will have swappable end effectors, or maybe tools will be specifically designed with attachments for robot hands, but there’s no reason not to think that, at scale, you gain more from good, vertically-integrated design than from building something to support legacy hardware (humans) forever. Indeed, a modular robot like Atlas could eventually use these tools better than a human ever could.
At best, I think the robot tool use argument will be a short-term cost-saver that applies over the next couple years.
This is a vastly better argument in favor of human mimicry, but the cracks are starting to show even here. Human teleoperation data, while essential for robot learning to this point, will not be able to take full advantage of superhuman humanoids.
But there are ways around this, and one is something we absolutely need no matter what: reinforcement learning. Says Atlas product lead Mario Bollini again:
Reinforcement learning is crucial for real-world reliability, as demonstrated in recent works like Probe-Learn-Distill from NVIDIA and RL-100 (both are RoboPapers podcast episodes you can watch/listen to). It also provides a way for us to start with human demonstrations but then improve upon them.
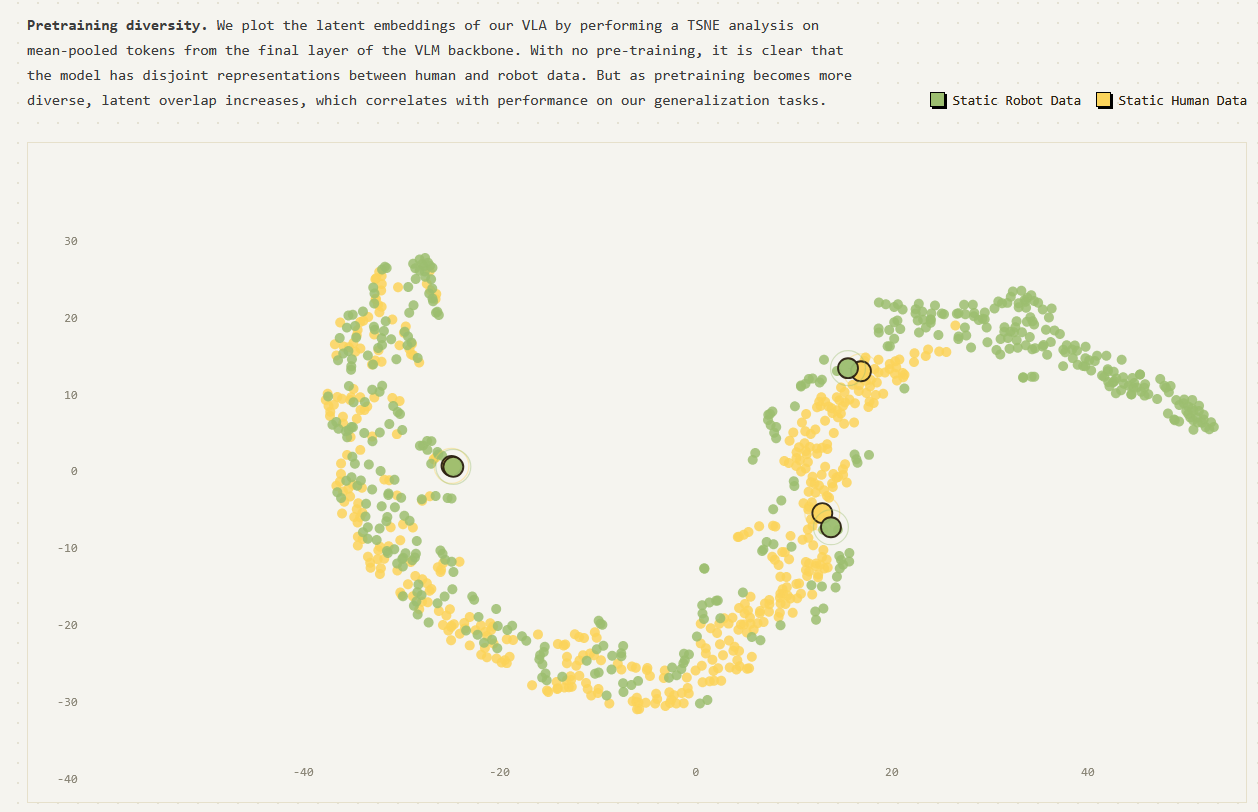
But what about human video data? Certainly, there’s compelling evidence that video data can improve performance with humanoid robots. I’ve discussed the importance of co-training on this blog before: how else could we ever we get enough data to train a Robot GPT?
But your robot might not need to be human to take advantage of video data. Take a look at the the recent “Emergence of Human to Robot Transfer in VLAs,” by the Physical Intelligence team. In the plot above, the show how just by co-training on human and robot data, the models naturally learn a similar embedding space for tasks which is shared across the different embodiments.
And PI’s robots do not look remotely human! They’re very simple, lightweight research arms with two-finger grippers. Now, they’re not performing highly dexterous tasks in this case, and this might change, but I see no reason why as long as the robot hardware is capable of a task, that such a shared mapping cannot be learned.
As a final note: I don’t think there’s any particular reason human hands have five fingers. Dogs have five fingerbones, as do whales; neither of these animals use these at all. Humans have hands with five fingers by accident of evolution, nothing more — it is not the product of some optimal engineering process. And so I don’t see why our robots should be limited to that, either.
The humanoid form factor is, I think, here to stay due to its clear advantages, but that doesn’t necessarily mean that it will stay human. The Atlas is an interesting look at a very different vision of what a humanoid robot can and should be, and I think it’s exciting to see it come to fruition with a new model designed for mass production.
I also think there’s a huge opportunity here. As I mentioned above, one advantage of robots that look human is that you understand what humans can do. With a totally “alien” design like the new Atlas, the roboticists can rewrite the script: you know what a human can do, but also what Atlas can do. That kind of product identity will, I think, be very valuable as we approach a sort of “jagged” physical AGI in the coming decade or decades.
Please let me know your thoughts below, and share/like/subscribe to help others find this if you found it interesting.

On December 23, 2025, the Ukrainian military announced that a robot from DevDroid, a domestic producer of combat robots, had held a position near Kharkiv for roughly 45 days against sporadic Russian attacks. Employed by the 3rd Separate Assault Brigade of the Ukrainian Armed Forces, this deployment is emblematic of how these robots are becoming more important in the grueling attritional warfare in Ukraine.
This particular event marks something of a milestone for ground robots, which are used by Ukraine for roles like reconnaissance, resupply, infantry support, and rescuing wounded personnel. Ukraine’s military is particularly focused on robotics deployment, with their goal being to deploy 15,000 unmanned ground vehicles (UGVs) — among them at the very least hundreds of DevDroid platforms — by the end of 2025.
This might seem strange to some: after all, aerial drones are the iconic face of robotic warfare. The DJI Mavic is particularly iconic; as one Russian military blogger recorded, “Mavic means death.” This sentiment — and the overwhelming superiority of Chinese dronemaker DJI — led the United States to implement a ban on the import of such systems from China. Ukraine’s Operation Spiderweb and Israel’s decapitating strikes on Iran during Operation Rising Lion would not have been possible without these transformative platforms.
But there are roles for which these smaller kamikaze platforms are not particularly suited: the war is currently a grinding attritional battle, with brutal trench fighting that has consumed hundreds of thousands of human lives already, leaving both sides scrambling for more personnel to fill the ranks. And, of course, reaching for technological solutions.

We can go on and on about the potential of small, disposable aerial drones in warfare (read my previous blog post, for example). These lightweight, low-cost machines are effective at eliminating enemy infantry and armor; they provide reconnaissance support; they mount ambushes. The Armed Forces of Ukraine received about three million first-person view (FPV) drones in 2025.
But these are not the only aims for warfare. In the end, war is about holding ground. Aerial drones may excel at engaging enemy forces, but arguably they’re just acting as a lightweight replacement for artillery. They can certainly engage the enemy; it’s been reported that drones cause 70% of casualties in Ukraine.
Note, however, that in World War II artillery and air strikes caused 50-70% of casualties. It’s not like the drone is replacing an infantryman. Inflicting casualties, largely, is not their job and has not been their job through much of history. Instead, as Napoleon Bonaparte said:
The hardest thing of all is to hold the ground you have taken.
This is where I think these ground drones come in, and why they have a very distinct role compared to the aerial variety (loitering munitions). Much of the Ukraine war is actually what appears to be almost old-fashioned trench warfare, with human soldiers digging in to hold territory against their enemies.

It may surprise some users that we even want or need ground robots instead of just relying on swarms of drones, so let’s go into what these robots are actually doing a little bit more. There are two main classes of armed unmanned ground robots from DevDroid:
The machine-gun-armed TW 12.7, recently approved for use by the Ukrainian Ministry of Defense
The NW 40, armed with a rapid-fire grenade launcher, used for ambushes against light armored vehicles and enemy convoys, and recently codified (officially inducted into service for state procurement)
In addition, we see many other types of ground robots — kamikaze ground robots, logistics/supply carriers, and others for evacuating the wounded. Many of these are useful for mounting ambushes or for protection against them (in particular using autonomous robots to resupply).
Probably the most important role these robots are serving is to keep soldiers out of line of fire. Robots like the Devdroid or the similar T-700 carry fairly heavy weapons. They can perform fire missions and suppressive fire, and conduct ambushes without exposing human soldiers the enemy. And a lot of what human infantry do, unfortunately, is dig in somewhere and get shot at.
When a robot is "holding a trench” for 45 days, it won’t have spent all of that time taking enemy fire — but it was important to that someone be there, at that intersection of trench lines, who could fire on approaching enemies and take fire in turn.
This process of trading fire creates friction between the two opposing forces, and most likely once the robot starts shooting, the enemy would fall back. If they actually wanted to take that position they might call for artillery or — yes— aerial drones. If no one was there to oppose them, they might just break through, and be able to interfere with supply lines or just seize ground, dig in, and call for reinforcements.
Both sides will start shooting well before any casualties are guaranteed or even likely, at least in any particular engagement. In the American War on Terror, US forces expended something like 250,000 rounds of ammunition for every insurgent killed. But the act of firing on a position — of putting vast amounts of lethal power downrange — forces soldiers into cover or retreat to avoid harm. It prevents movement, and locks down a whole area, even if the engagement between the two forces was very brief.
And this is why a bomb-armed quadrotor — or even 50 quadrotors — can’t do the same job. The gun-armed robots we see here can move around, take some measure of cover themselves, and are armored enough to be quite resistant to explosives and even the occasional suicide drone. They can threaten a very large area — engagement ranges for these weapons run from 50 to 800 meters — and prevent enemy movement through a large part of that area, for days or weeks at a time, all without endangering soldiers on their own side.
It’s a very different part of the puzzle that is a modern battlefield: as opposed to being disposable, high-precision “light artillery” like aerial drones, these robots are acting like infantry or “light tanks.”

As noted above, these robots are not autonomous. But this is likely to change, and it might not be very long before it does — and the reason comes back to aerial drones. Basically, today’s militaries badly need an economical solution to keeping the “lower skies” clear and their troops safe (or, at least, as safe as it gets in a warzone).
Currently, counter-drone efforts are largely a manual affair, using specially-equipped interceptors which, themselves, are human-piloted FPV drones. More autonomous and scalable solutions exist, but often interceptor missiles end up being more expensive than the robots they are shooting down!
This has led companies like Anduril and Allen Control Systems to start building autonomous gun platforms which can automatically detect, target, and shoot down fast moving drones. Think, similarly, to the Phalanx CIWS on American carriers: these shoot a lot of bullets (relatively cheap) to take out the incoming drone while protecting humans on their team.
There is, rightly, a lot of debate about robots making the decision to shoot against humans, and the United States Department of Defense still says humans will stay in the “kill chain” at all times. But if they’re just shooting down munitions, presumably, there is no issue.
Of course, as countermeasures (to remote operation of these robots) grow stronger, and artificial intelligence gets better, who’s to say that robots won’t start to be trusted with more and more autonomy when handed other targets?
The old cliche goes that necessity is the mother of invention. Many of these current combat robots exist to solve for very specific problems the Ukrainian military faces, particularly a lack of manpower.
But these still feel like they presage future warfare in important ways. These machines will appear first to help hold ground, and to secure the lower skies against enemy drones — but if the need arises, they’ll be doing more than that.
If you like this, or have any thoughts, please let me know below.
To learn more, read my previous article about aerial military drones below.
]]>
When a technology finally clicks, the changes spread faster than anyone expects and have far more serious implications for society. I want to lay out a case here for robotics finally “clicking” within the next few years, and what that could look like for everyone. Technological change happens fast, and nowhere is that more obvious than in the early part of the 20th century.
There were 130,000 horses in New York City around 1900. By 1912, they were already outnumbered by automobiles; today, there are only 68 licensed carriages and probably a mere 200 horses in the entire city now. Despite peaking at 26 million, the United States population of horses went down to 3 million by 1960. As soon as the economic utility of the animals vanished, they disappeared from public life and the city changed forever essentially overnight.
In 1908, maybe 1% of American households had a car. This number tripled in the 1920s, going from 8 million to around 23 million. By 1948, half of all households had a car; by 1960, it was 75%. The shape of American cities changed completely over this window.
Predicting the future is very difficult, and the core problems in robotics are far from solved, but I think we’re seeing a very similar period of rapid change happening right now. The level of investment and growth in robotics and AI is reaching a fever pitch, well beyond what I expected 1-2 years ago. And, perhaps more importantly, most of what I have believed are substantial blockers to robotics deployments now seem solvable on a technical level:
Robots are relatively cheap, mass-produced, and of increasingly high quality, with a robust supply chain.
Data issues that have stymied robotics learning in the past look addressable.
Core learning technologies — both supervised training on large datasets and reinforcement learning in the real world — have been proven out.
All this means that we should see robots in a lot more industries and parts of society than we’ve ever seen in the past, so let’s talk about the future. But first, let’s lay out the case for robotics optimism — then we can get into what it means.

The big story of 2025, for me, is the sheer scale of production of humanoid robots. Companies like Agibot and UBTech are building humanoid robots by the thousands now, and sending them to work in factories belonging to the world’s biggest automakers — companies like BYD.
In general, the number of humanoid robotics companies, and teams working on humanoid robots, is skyrocketing. Most recently, Rivian announced that it is spinning off Mind Robotics, with $115 million in funding. Said founder and CEO RJ Scaringe:
As much as we’ve seen AI shift how we operate and run our businesses through the wide-ranging applications for LLMs, the potential for AI to really shift how we think about operating in the physical world is, in some ways, unimaginably large.
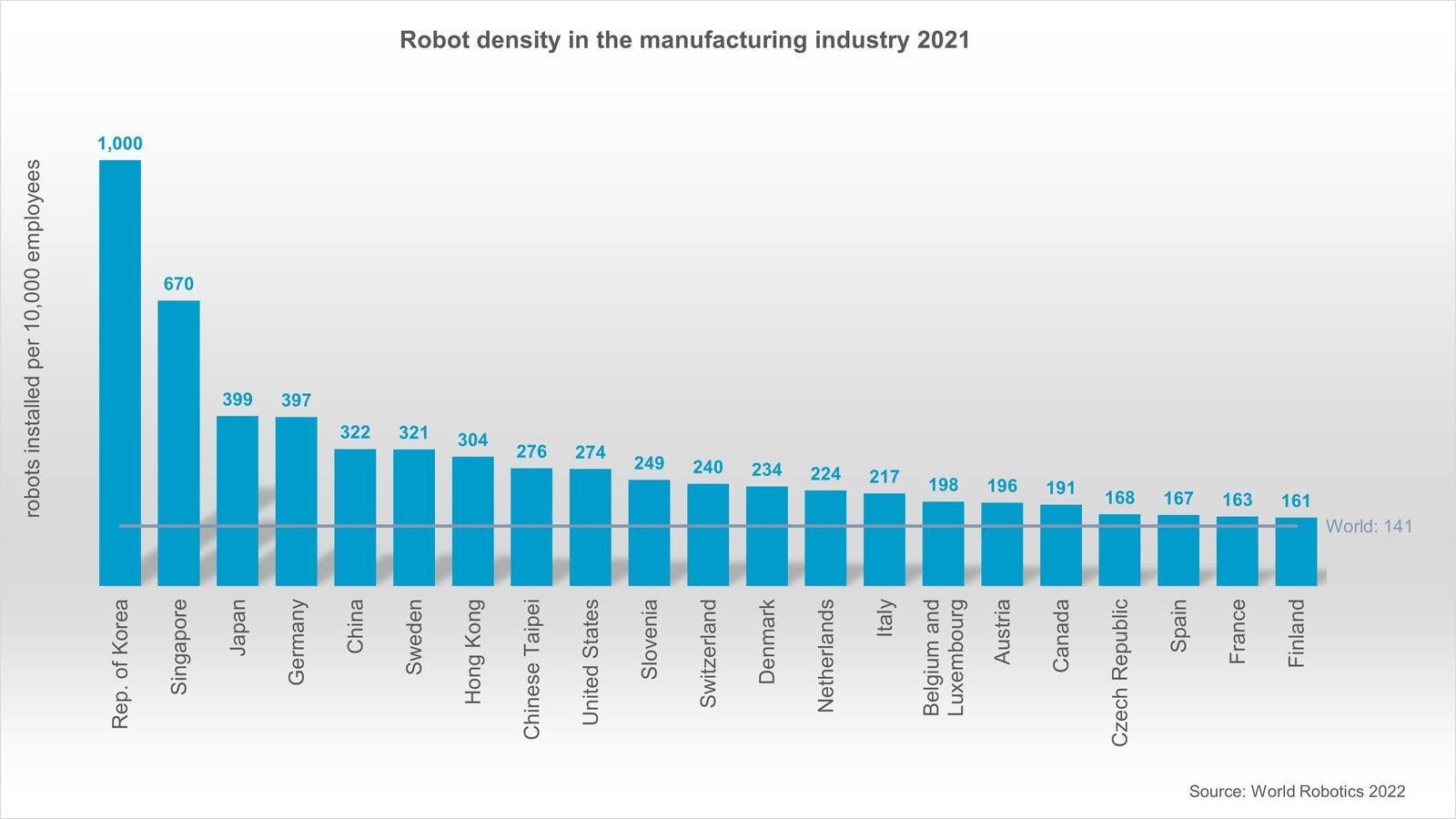
An explosion of investment like this is never due to just one factor. In fact, several things have come together to produce this moment. Quality robots are getting incredibly cheap. The Chinese supply chain is getting very strong, making it easier for new entrants to build at least a v1 of their products. Hardware expertise is getting more widespread.
Techniques for robotics control and learning have become more mature, and have overcome a few major limitations that we’d seen in the past around mobile manipulation and reliable real-world performance. Partly as a result, companies like Unitree and 1x have demonstrated that there is real demand for robots from consumers, with preorders and widespread hype for 1x and exploding G1 humanoid robot sales for Unitree.
Finally, it seems that the robotics “data wall” is becoming less of an issue. Data collection and scaling is much easier than ever. A number of companies like Build and MicroAGI have appeared to scale up human-centric data collection; research work like EgoMimic has provided at least a feasible route to collecting data at scale (watch our RoboPapers podcast episode on EMMA here). Companies like Sunday Robotics are demonstrating how effective scaling with UMI-style tools can be (see our DexUMI episode on RoboPapers here).
When I was in graduate school, this thing cost like $35,000:
And I’m talking just the robot arm - the Universal Robots UR5 - not the gripper, camera, monitor, GPU, et cetera. It was a pretty good platform, but back then the Robotiq 2-finger gripper alone was also probably about $12,000 — totalling about $62,000 when adjusted for the inflation we’ve seen since 2016.
These days, I could buy four Unitree G1s for that price (base model), or, for a slightly fairer comparison, one Unitree G1 EDU plus. I could also buy a LimX Oli. I will soon be able to buy a Unitree H2, a full-sized humanoid robot (probably $60,000-$70,000 USD, tariffs included).
Buying incredibly powerful, capable robots has never been easier: for less than the price of a mid-range sedan, you now can purchase a robot that was impossible even with DARPA funding just a decade ago. And all of these robots have a much more robust ecosystem: the robotics community has, practically overnight, become absolutely massive. Mass production has given us robots which are both cheaper and substantially more capable — as well as just more fun — than was true less than a decade ago.
And this has downstream effects, because a huge part of what makes it hard to automate stuff just comes down to price! Specialized hardware is expensive, but you need specialized hardware less and less — there are so many more options now. The expertise is more available. The hardware is more robust and easier to use. Lower cost makes the entire robotics ecosystem much stronger than it used to be.
We’ve all seen a number of incredible dancing and martial arts videos from companies like Unitree. While these are impressive looking, they don’t demonstrate fundamentally useful robot capabilities, because they don’t interact with the environment. It’s relatively easy to program a robot that doesn’t need to collide with stuff; any dumb technique you can think of these days will work for building a robot that doesn’t need to interact with the environment.
Interacting with the environment, though, is tough. It’s hard to simulate; it requires a ton of real-world data to adapt properly. Getting the correct examples of physical interactions is very hard. I’ve spent much of my robotics career working on long-horizon robot tasks, and at this point the problems are very rarely due to high-level planning (the robot decided to do the wrong thing), but more often due to difficulties with environmental interaction.
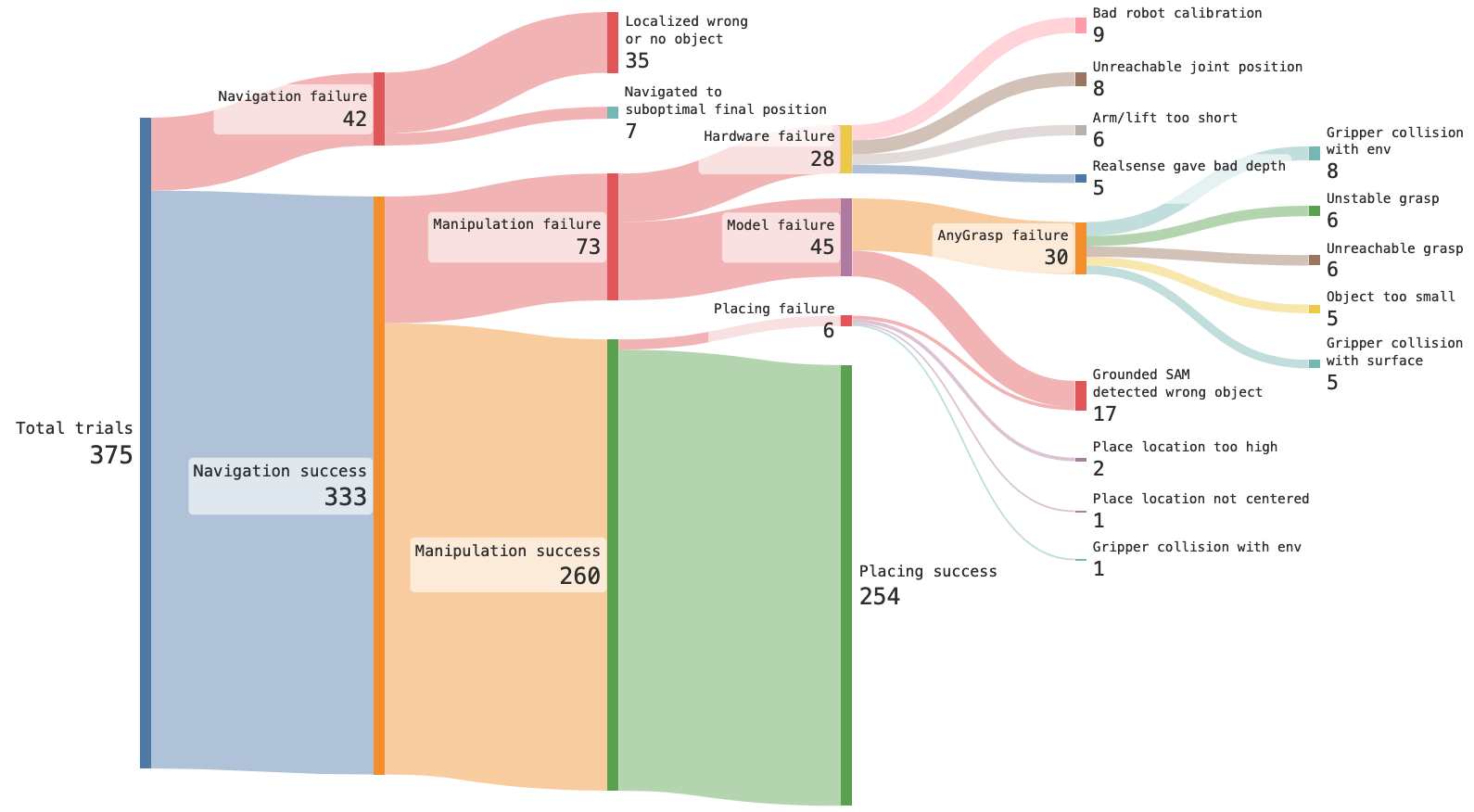
You can take a look at the plot above from the OK-Robot (a 2024 paper) to get a sense for what I’m saying. A lot of the time, the robot can’t reach something (navigation failure); other times the hardware fails; other times it just can’t reliably grasp something due to a model not properly handling the particular combination of environment and object.
If robots could be made to reliably perform real-world manipulation tasks beyond structured picking, this would be a big deal. So I want to draw attention to two specific results that were extremely important this year: whole-body control with mobile manipulation, and real world reinforcement learning.
The video above is from RL-100, recent robotics research from Kun Lei et al. from a variety of institutions but mostly the Shanghai Qizhu Institute. It shows a robot arm working in a shopping mall — an out of distribution environment — while juicing oranges for seven hours.
We’ve similarly seen work like pi-0.6* from Physical Intelligence, which showed robots performing tasks like building cardboard boxes and making espresso drinks, reliably, in a way that humans might. And I’ve already written about folding clothes — startup Dyna Robotics started there but has since moved on to demonstrating high reliability in end-to-end learning with other tasks. Now, none of these tasks are revolutionary on their own, but achieving these levels of reliability with end-to-end systems in the real world absolutely is.
More importantly, the idea that there will soon be a recipe for deploying such skills is crucial. By analogy, look at ChatGPT and the broader adoption of LLMs; previously there were many different image- and text-recognition tools. Model large vision-language models like ChatGPT removed the barrier to building systems that leverage text and images; they provide sort of a shared interface. Even if that means running some on-robot RL procedure where someone types 0s and 1s for failures and successes into a spreadsheet, it seems that we could arrive at similarly highly useful systems for robots.
But these advances, just like the ones we’ve seen for large language models, are all likely to be predicated on strong base models, just as we have seen for LLMs. Famously, the reinforcement learning that made Deepseek R1 such a breakout success was only possible because of the quality of pretraining making the reinforcement learning problems tractable.
The base models of robotics are usually called Vision-Language-Action models or sometimes Large Behavior Models (there’s actually a small difference here, but they’re accomplishing the same thing). I’ve also written about it as a direction for future VLA research. The question has always been where to get the data.
What’s changed is that now broad, diverse robotics data seems achievable, through a collection of different tools. While certain things seemed to be false starts (mass teleoperation data is too expensive, mass simulation often too difficult to tune for contact-rich tasks), there are other really good options which have come into their own this year: egocentric video data and “UMI”-style tool data.
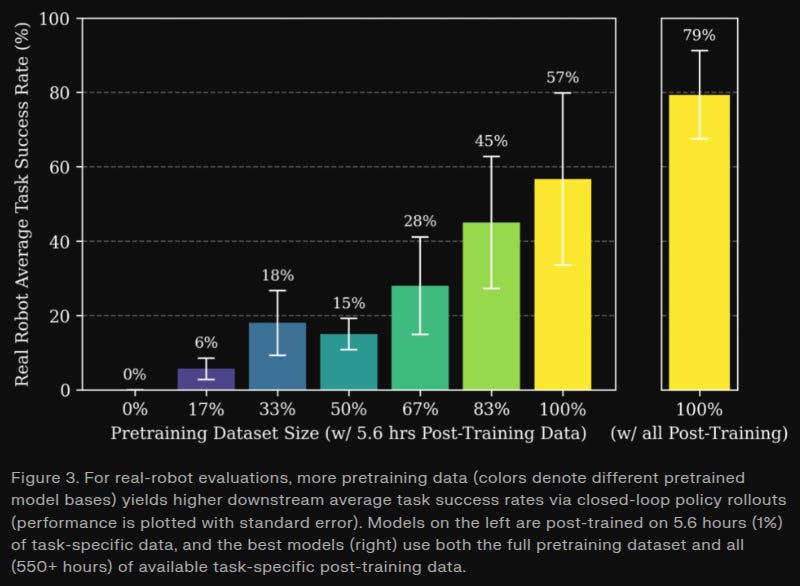
Generalist goes into detail on their recent GEN-0 blog post, describing how diverse pretraining data leads to faster posttraining of their robot models. We’ve also seen from Physical Intelligence that as models scale, they start to learn to treat human data as “just another modality,” meaning that they can start to leverage it to improve performance on various skills. At some point, once we have enough data, this implies that a lot of data-related problems may fall away far faster than previously expected.
A number of companies have sprung up around this idea, including Build, which produces huge quantities of camera-based manufacturing assembly data from human workers, and MicroAGI, which gets rich, high quality data from workers in different industries.
Broadly, it seems more likely than ever that the “eternal” robotics problem of not having enough data, will be solved in the coming years. And unlike in my previous estimates, I no longer believe it will necessarily be some billion-dollar project — which means many companies will be able to build powerful autonomous systems.
Large language models have also made dramatic progress in the last year. OpenAI’s o1 — the world’s first “reasoning model” - launched towards the end of 2024. Its success led directly to the release of Deepseek R1, which was a spectacularly important paper that described publicly a lot of the “secret knowledge” kept in house at OpenAI and has allowed for waves of successive exploration.
And the changes have been extreme. Coding is incredibly different from what it was just a year ago; it will likely never be the same again. Never again will I just write a whole project, token by token, by hand. These changes are appearing in many different industries: people raise concerns about AI replacing lawyers — increasingly many lawyers just draft everything with ChatGPT anyway. Similarly, 67% of doctors use ChatGPT daily, and 84% of them say it makes them better doctors. GPT 5.2 was evaluated on GDPval, a set of economically-valuable tasks, where it achieved equal or better performance than an in-domain human expert 70.9%.
Large language models are already significantly changing the way people work and rewriting the economy, like it or not. And these changes seem to be propagating far faster than the changes we saw with automobiles at the beginning of the 20th century, having propagated through society with all the speed of the internet. Robotics won’t spread so fast, but unless serious obstacles manifest (such as a total collapse of funding for R&D), it seems plausible there will be similar changes in the physical world.
To go back to the metaphor at the start of this blog post: when horses vanished from American cities, they didn’t just lose their jobs. The whole infrastructure of cities changed: hay and stables were replaced by gas stations and parking garages. Manure was gone from the streets, replaced by exhaust fumes. The feel of a city, even walking around on foot, now revolves around cars, with wide, flat asphalt roads and traffic lights on every block. Similarly, if the “optimistic case” from this blog post holds true, we should see significant changes in the fundamental details of life.
So, to recap: we have seen a year of dramatic robotics progress which for the first time showed the viability of long-running end-to-end robotics manipulation, at the same time the cost of robotics hardware is collapsing and its quality is exploding. We have seen dramatic changes in the world of purely-informational artificial intelligence, through reasoning models and agents.
I believe I have motivated this “optimistic case” well enough now that I am allowed to speculate a bit, as I promised at the beginning of this blog post. To start, we may make a couple assumptions about robotics over the next several years:
The robotics “data gap” will continue to close, and robotics will start to pick up speed due to the combination of more robots and more tools for making robots possible to use and deploy
AI will be at the heart of this — both reinforcement learning and imitation learning will be key parts of the solution, as elaborated in my previous blog post on VLA research directions
This means that a lot of areas of robotics which were previously inaccessible to automation soon will be. In fields like construction, we have thus far been limited to incredibly simple and structured pieces of automation: specially-built roofing robots, for example. Similarly, much of manufacturing is already automated, but that automation relies heavily on specialized systems, sensors, end-effectors, and machinery. All of this makes automation extremely expensive.
At the same time, the labor markets for fields like construction and manufacturing are getting worse. The world has filled up in a way; our countries are graying. We expect the ratio of workers to retirees to go down, requiring each individual worker to be far more economically productive. Those same retirees will need care and companionship that humans are unlikely to be willing or able to provide. All of this means that the world of 2030 will be far more robotic than that of today.
By 2030, users will be able to create and share their own use cases, as this is where true explosive growth starts to happen.
I expect we will see far more robots essentially everywhere. Waymo and its competitors will expand to more and more cities; fewer people will use their personal vehicles to get around. If they do, their vehicles will be using Tesla or Wayve autopilot systems to get around.
Robots will be in homes. They may or may not be humanoids. But they’ll be able to perform a wide range of simple manipulation tasks, things like picking up and perhaps putting away the dishes. They’ll cost less than a car, possibly in the $10,000-$20,000 range for a very good one. Robot production will still be ramping up this point, so it’s probably still less than 1% of households that have an in-home robot — but it’s going to be rapidly increasing into the 2030s, until it reaches similar levels to cars by 2040, with 50% or more owning an in-home robot that can help do chores.
These home robots will often be companions first; modern AI is extremely good at companionship. It is striking to me how much for example my two year old daughter likes to interact with even very simple home robots like Matic and Astro; more capable and intelligent LLM-powered home robots will be far more compelling friends and “pets.”
Most importantly, this will also lead to the “iPhone moment” for robotics, which is when acceleration will really take off. Some — such as Sunday Robotics founder Tony Zhao — have publicly alluded to this moment coming. What we hope is that by 2030, users will be able to create and share their own use cases, as this is where true explosive growth starts to happen.
In manufacturing and industry more broadly, we’re already seeing “systems integrators” start warming up to widespread use of end-to-end artificial intelligence. As the core technical competencies for deploying robotics models and post training them for specific tasks start to diffuse, I expect this to become very common.
Perhaps by 2030, you will order a set of robots for your factory and hire a consultant to train them for a couple days if you’ve never done so yourself. Eventually, though, this seems like an economic efficiency that will largely be done away with. You don’t usually hire an external contractor to integrate an LLM into your workflows; robots should be no different.
I started this post with an anecdote about horses being replaced by the automobile, but so far I really haven’t discussed what, exactly, the horses are that are being replaced. These metaphorical horses aren’t people, not exactly, but they are jobs currently done by people. Software engineering, for example, is clearly harder to break into now than it used to be. An individual experienced programmer is so much more productive with AI as a “force multiplier,” which means that less people are necessary to build and deploy complex software products.
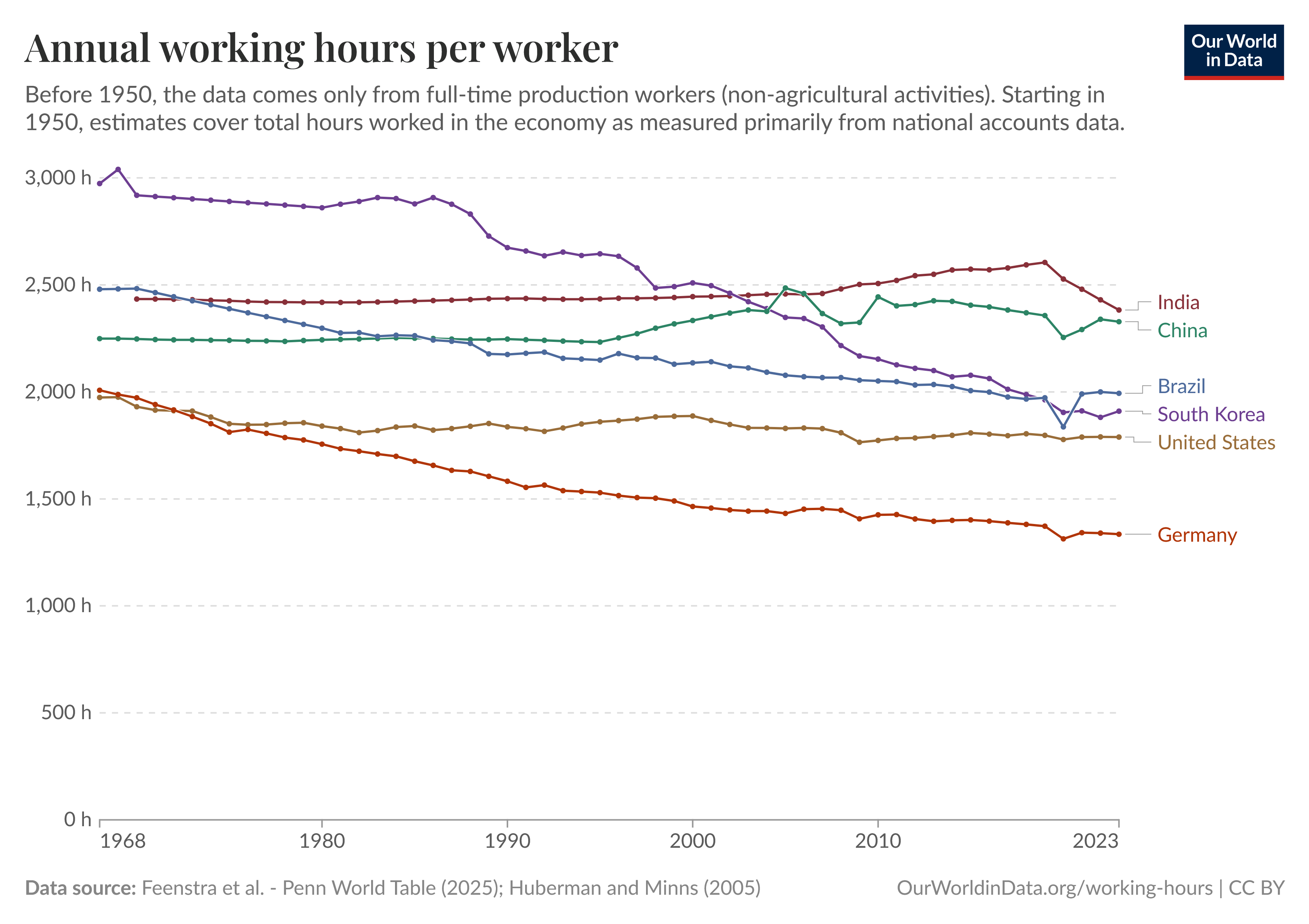
We should expect to see similar trends across basically every industry: more highly paid experts being far more productive, building more things, but each individual set of expertise being basically priceless, with robots handling more and more of the easily-replaceable labor. We should not fear this: in the developed world, working hours have largely been on a downward trend for decades, and it seems likely this will continue. Many human jobs will amount to handling the long-term planning and coordination that AI and robots seem persistently bad at, and intervening when they fail; but this should make for comparatively easy and low-stress work for a great percentage of the workforce.
It’s strange to look back at my own predictions for robotics from the end of 2024. Back then, one of my chief concerns was how to build scalable “world representations” for long horizon reasoning. This remains a concern to me; I’ve honestly seen basically no significant progress in this space. There are impressive 3d world models now, like that of World Labs, but these are all generally creating single scenes, not modeling their evolution in response to new sensor data. For true embodied general intelligence, we still need to address these fundamental questions about how robots will represent their knowledge of the world over time.

In some ways, it’s a good thing: the blocker for deploying long horizon reasoning has never been that long horizon reasoning is all that hard, it’s always been that execution is hard and that robots break (see, again, the Sankey diagram above from OK-Robot).
This also will still require lots of funding. Fortunately, it seems that many investors and billionaires with deep pockets — Jeff Bezos, Elon Musk, and others — are “all in” on artificial intelligence and robotics. Very likely, the money will not run out. But if it does, all this could come to a premature end.
And finally I worry about the closing-off of ecosystems. Open robotics innovation right now is championed, largely, by Physical Intelligence and NVIDIA, with some great recent entrants from Amazon FAR. While many of these problems are being solved, we still need new ideas and open dialogue to solve them — if all our doors and windows close, it’s possible the field stagnates and nothing gets accomplished.
With robot hardware getting so much better, with methods becoming mature and real-world results and long-running demos becoming somewhat common, I’ve never been more optimistic about what robotics will be capable of.
Part of the point of writing this is to point out how fast things have changed. And this is not unprecedented! I started this blog post with an anecdote about the horse being replaced by the automobile over just a couple decades. It’s not unreasonable to think that — in a lot of ways — we’re heading for such a moment. Not next year, not in two years, but over the next decade? It seems inevitable.
Basically all robotics problems get easier at scale: hardware related, deployment related, and data related issues all become much more tractable as soon as there are a lot of robots out there in the world.
I believe very strongly that we’re on a great trend, that these technologies will diffuse through society over the next 5-10 years, and that the future bright. But we’re headed for a very different world than the one we live in now, and that’s something we’ll also need to wrestle with over the coming years.
]]>
The future of industrial production is automated. From our ports to trucking and last-mile delivery, robots are now involved in nearly every part of bringing people the products that they want. And yet in a lot of cases the production of these products themselves is not yet automated; they are still built by specialized human workers. Even in wealthy, developed countries like the United States many things that seem as if they should be automated are not.
Take the example of Nike trying to near-shore production of shoes from Vietnam to Guadalajara, Mexico, as described in this Wall Street Journal article by Jon Emont. Shoe manufacturing relies on an army of skilled workers to perform fine manual labor, stitching and gluing a very wide variety of shoes together.
Ultimately, this effort was unsuccessful; Nike ended up closing the facility, and most shoes are still made by hand as of the writing of this article. And Nike isn’t the only example; small manufacturers in the United States rarely employ automation, far less than in near-peer countries like China or Germany.
There are a variety of reasons that automation seems to be taking off at different rates, ranging from technical to economic. Let’s go over some of the whys here: why automation is hard, where it fails, and why it seems to be moving faster in some areas than others.
If you like this blog, please consider subscribing, liking, or leaving a comment. Liking and subscribing helps others find these posts!

Industrial automation actually works very well within its narrow operational constraints. So-called dark factories have existed since 2001, when FANUC began lights-out operations at its flagship facility, with robots producing other robots wholly in the dark for up to 30 days at a time, completely unmanned.
These dark factories have become an iconic feature of Chinese industry, with giants like Xiaomi and BYD increasingly employing them to mass-produce products like smartphones and cars.
But all of these products have something in common: with smartphones, or cars, or industrial robots, you might be building millions of units of product with very few variations. This justifies the larger up-front cost of traditional automation, which involves carefully designing assembly lines, planning robot placement, and even planning individual movements the robots will be making in perfect synchrony months ahead of time.
This is, to say the least, an incredibly expensive undertaking. It’s the work of systems integrators, companies that focus on building a particular class of robotics automation solutions. They will plan camera placements, write code, hook up sensors, design custom tools or parts — whatever is necessary to produce the perfect fully-autonomous production line.
Above: video of a small Chinese machine shop by Marco Castelli on X
Benjamin Gibbs of Ready Robotics wrote a thread on X a while ago, listing reasons why you don’t see more robots deployed, especially looking at small and medium-sized enterprises (SMEs). In short:
Skepticism: the idea that many people know someone or have themselves tried to deploy a new industrial robot, and have not gotten a good return on their investment.
Opportunity cost: for a small, low-margin producer, spending $50,000 on a new robot makes a lot less sense than buying a new tool (also very expensive!) which can open up new revenue streams for the company
Software complexity: note that this is not the complexity of programming the robot, but of integrating various vision and safety systems, connecting to industrial PLCs, and so on. Each integration can be a massive undertaking with many different programming languages and (usually poorly documented) software packages involved.
Tooling design: industrial robots, as they are currently used in the United States, require very specialized end effectors to be useful. There is still no “universal” robot tooling; you cannot just order these parts off the shelf. Companies like Right Hand Robotics which once aimed to build more broadly-useful grippers and tools have always ended up narrowing their ambitions substantially.
Parts presentation: basically, the “art” of building a reliable input system for parts to arrive at the robot; almost every one of these has historically been custom-made and is therefore wildly expensive.
Electrical complexity: because there are so many custom parts and sensors, a shop looking to automate will need a custom electrical panel. They’ll need someone with wiring experience that they almost certainly lack in-house.
Let’s go back to the Nike example above. Their hope was that they could reproduce successes in building microprocessors, but applied to this new domain. Shoes are representative of a lot of the issues that robotics problems struggle with:
The wide variety of shoes produced, all with subtle differences, increases the human effort necessary to handle the full range of products during the process of automation systems integration
Similarly, the fact that shoes are made out of deformable materials means that the number of special parts and designs needed to fixture a shoe properly to grasp it 99.99% of the time and automate a full production line is extremely high
Safety sensors and integration requirements exist for partially automating production, which would not exist for a setup that’s not automated
Integrating all the specialized hardware used by a traditional systems integrator will be nearly impossible.
And the problem gets worse.
In 2021, China overtook the United States for number of robots deployed in manufacturing. By 2025, they’ve also overtaken anyone else, becoming the leading user of industrial robots in the world. This is not because of some technical edge — the bleeding edge of technology exemplified by companies like Physical Intelligence remains solidly American — but because of a complex ecosystem that enables production and deployment of robots economically and at scale.
As Andreesen-Horowitz noted in their report on robotics automation:
There are no “dark factories” in the United States. The closest that we have is Tesla’s Gigafactory Nevada, which is 90 percent automated. No other major manufacturer comes close.
Deployment costs and “cost disease” are endemic in many areas of American industry, and manufacturing appears to be no exception. As a result of these deployment hurdles, we often see that companies deploy robots only because they are forced to, usually by labor shortages.
It’s also noteworthy that, as mentioned above, current industrial automation requires a large number of custom parts, which means that the best returns will only appear at the very largest manufacturing scales. Without a robust ecosystem for custom systems integration work and a broad depth of expertise in the market, integration costs will remain extremely high.
So, in a way, it could be argued that we don’t use many robots, because costs are high, and costs are high because we don’t use many robots. This is a place where government action has worked in China, where there are often 10-20% up-front cash subsidies available for manufacturers. While the USA has similar incentives American subsidies take the form of tax breaks (such as Section 179), which necessitate extra legal fees, overhead, and for the company to take that extra cost burden ahead of time anyway only to be “paid back” later. It’s perhaps a less efficient way for the government to spend the same amount of money.

In the end, we have two types of problems: shortcomings of current technology and shortcomings of the broader economy that make automation less tractable in the united states. Aggressive competition in manufacturing has led to better returns on scale, both internally to companies and to the country as a whole which benefits from robust supply chains, expertise, and labor markets.
But technology, here, might be a way out. The factory of the future probably does not use the wide range of specialized sensors and fixtures that Ben Gibbs mentioned in his thread. Modern vision-based AI systems are pretty good at handling deformable materials like clothes. Companies like Dyna and Physical Intelligence have shown dual-armed mobile platforms that are both reasonably affordable and capable of performing an extremely wide variety of useful tasks to a high degree of reliability, if not particularly quickly (yet).
The difference here is massive. These newer, lower-cost robots are safer to be around, they’re cheaper to replace, and they don’t need the massive diversity of custom sensors or fixtures to work properly. Instead, because they work by seeing the world like humans do, they can be placed in a production line more or less the way that humans are, with only a fairly labor-intensive bringup process to teach them a new skill. But note that this bringup process is still less labor intensive than the current arduous process undertaken by the systems integrators we discussed above!

Perhaps in the farther future, we’ll see things like the MicroFactory take off: a bunch of cheap, modular robotic cells designed to be deployed in a controlled work cell, so that you could easily parallelize reinforcement learning training and deploy the robots at scale on a large production line. We’re already seeing companies like Standard Bots working to reinvent the formula.
Real technical challenges remain around speed, safety, and the general capability of these robots — as well as how to make their training more scalable and make the hardware more reliable. But the future of robotics manufacturing, it seems, will come from Silicon Valley and Austin, Texas, not the traditional manufacturing centers of the US, and it will be software-first.
If you liked this post, please like, share, and subscribe; or leave a comment with your thoughts below.
]]>
Google has a new paper called Nested Learning which aims to enable lifelong learning in artificial intelligence by framing the machine learning optimization problem as a set of nested sub-problems [1]. In the authors’ words:
We introduce Nested Learning, a new approach to machine learning that views models as a set of smaller, nested optimization problems, each with its own internal workflow, in order to mitigate or even completely avoid the issue of “catastrophic forgetting”, where learning new tasks sacrifices proficiency on old tasks.
For robots and other artificially intelligent agents to be deployed “in the wild,” they will need to be able to learn on the fly, while not forgetting all of the other things they’ve already learned.
The way we usually do this right now is through clever tricks of context; for example, when you talk to ChatGPT, it will save additional memories as text. I actually have a really dumb version of this implemented in a Discord chatbot here if you want to see how well it works by experimenting on your friends and family.
But this has its limits. Context lengths grow, and memories require more and more “compression.” This form of memory is essentially just a more elaborate system prompt in a lot of ways, and so nothing fundamental will change. Ideally, we would see a version of this where the weights of the neural network themselves change over time, something more like how humans learn over time.
This is a problem we call Continual Learning or Lifelong Learning. If you want to read a bit more about continual learning in computer science, and what it might mean for human learning, you can check out this blog post by Beren Millidge called “Continual learning explains some interesting phenomena in human memory.”
The core insight in this work is that by treating the whole AI learning problem as a set of nested sub-problems, which makes it possible to avoid a crucial issue with current continual learning approaches. Let’s go lightly over how.
This is pretty different from my usual type of post, so maybe take a look at some other posts before clicking subscribe below (like this one or this one):
The core problem we want to solve with lifelong learning is called catastrophic forgetting. Let’s walk through a naive solution to see why.
Imagine I have a neural network which I’ve trained to perform some task, like say pick up cups around my house and put them back in the cabinet. I’ve collected a great dataset for cups: I have a whole variety of cups of different sizes and shapes and colors. I have all the places where they might go: these go in a cabinet, these fancy cups in a display case, and so on. Great. Call this dataset A, and assume I have some policy trained on this A.
Now, I extend this with new data to pick up toys off of the floor and put them in their boxes. I collect a new dataset with all kinds of children’s toys: action figures, stuffed animals, whatever. With them I collect a new dataset of demonstration locations to place these objects. Call this dataset B.
I continue training my model, which was originally trained on A, but now I am only training it on B. Unsurprisingly, when I next try to train on A, I see that I’ve now lost all performance on A — my robot can no longer put away cups properly.
Now, I already know the solution to this: I have to train on both A and B. The problem is that as I add more datasets — C and D and E and so on — the amount of data that I have to train on becomes cumbersome. I start to run into model capacity issues, or inference becomes slow, or I just can’t train on all of these fast enough.
Realistically, I want some way of updating my policy with a new dataset without hurting its performance on old datasets, but also without fully retraining on all my various datasets. The naive solution here — the most common and usually best solution — will be to just sample from all of the different datasets so I’m always retraining on a little bit of everything, according to my other constraints.
But that’s an awkward solution that requires you to store infinite data forever, so let’s see if these Google researchers can come up with something better.

In general, we solve this problem through modularity. In what limited work I’ve done on continual learning [2], for example, the proposed method resulted in multiple parallel robot policies, each of which was specialized to a different setting.
But that’s not really how the human brain works. We have memory that operates at many different scales: some longer term, some shorter term. Current transformers only experience the present: they basically have some baked-in knowledge encoded in weights, and they have their context, and that’s it.
The key insight here is that momentum-based optimizers like Adam are, in an of themselves, a sort of associative memory — basically a model. And so we can pose a learning problem as a set of nested optimization problems, all running at different speeds:
Inner loops update rapidly to capture new information (like the locations of the toys we wanted to grasp, from our example above)
Outer loops update slowly, capturing more general information (the structure of the home, perhaps).
This means that the slower outer loops can anchor new information and prevent the model from forgetting everything.
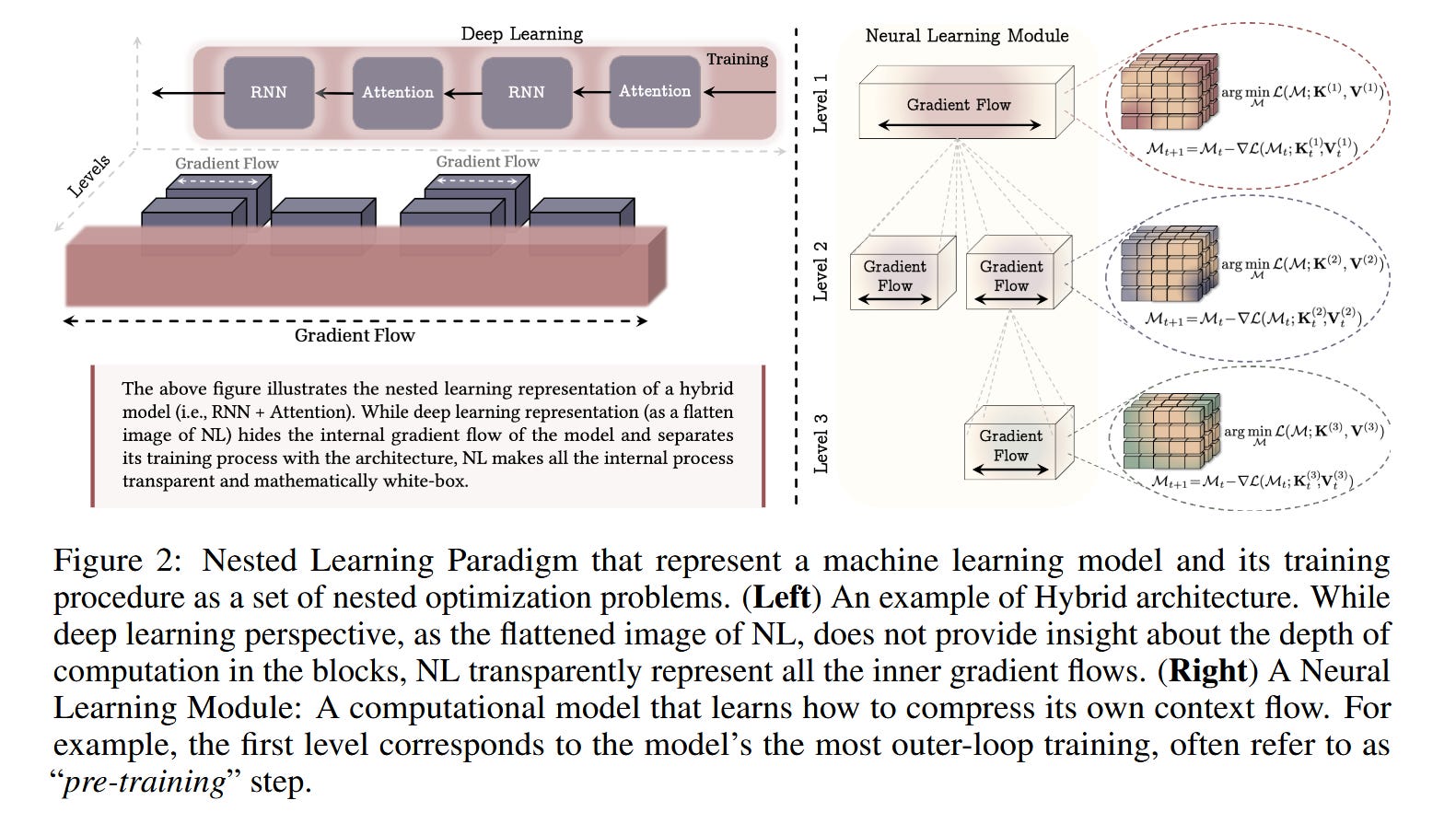
The core claim of the paper is that architecture is an illusion: that both optimizers (Adam, for example) and neural networks are the same thing: an associative memory. Since we will be talking a lot about learning and memory, the authors provide us with this helpful definition:
Memory is a neural update caused by an input, and learning is the process for acquiring effective and useful memory.
An associative memory, then, is going to be something which maps between different sets of keys and values:

This is an incredibly broad definition, which is sort of the point. So Attention is an associative memory mapping tokens to other tokens; Momentum (as in SGD) is a memory mapping gradients to updates. Optimizers like SGD are just very simple associative memories, which the authors proper replacing with “Deep Optimizers” that learn how to update inner networks.
So, training a single neural network as building a mapping between the data points in your training dataset and their local surprise signal in representation space (i.e. how well they match their objective), just over the training dataset examples.
This part is pretty straightforward interpretation of LLM training. Where it gets more interesting is in the next layer; a momentum-based optimizer then becomes a second-level associative memory, where the outer layer is updating the weights with based on the inner-level memory (again, basically prediction error).
We can follow this logic to phrase a machine learning problem as a set of nested optimization problems, where at each level it isn’t just learning a task but also learning how to learn the task. These levels all operate at different update rates — again see the analogy to the human brain above — with outer/higher level loops updating less frequently.
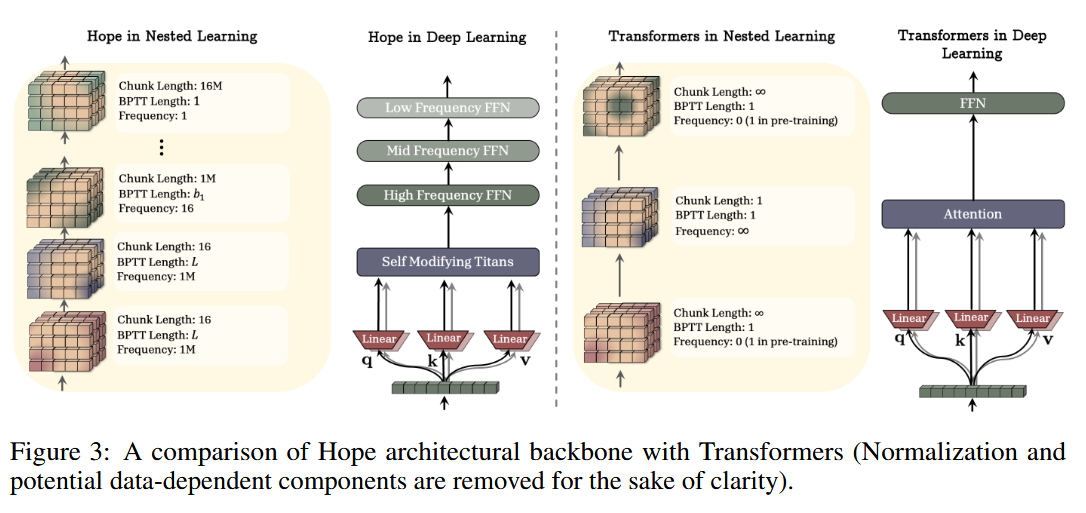
The authors go into more detail talking about how they can represent many well-known optimizers as special cases of nested learning, and go on to propose more expressive versions of optimization and of the underlying memory operation. They also propose HOPE.
HOPE is a “Self-Referential Learning Module with Continuum Memory,” which here means that it’s a chain of neural network blocks updated at increasing frequencies as they are nested deeper and deeper. To understand why, let’s consider the case of learning a Transformer for language prediction.
In a “normal” Tranformer trained with a discrete train and eval phase, we have two time frequencies that we care about; general, high level information is only encoded once, at training time, and local information is only encoded in the context window (hence in-context learning). But with HOPE, we have many modules, each learning how to update the one below it, and operating at different rates, which makes it much more adaptable.
Their proposed architecture builds on Titans [3]. Titans are a new class of model designed to improve memory, enabling remembering and forgetting over time (remember this is generally not something transformers do — they just rely on their long context windows!).
While this is all extremely preliminary machine learning theory, the results look promising for language modeling:
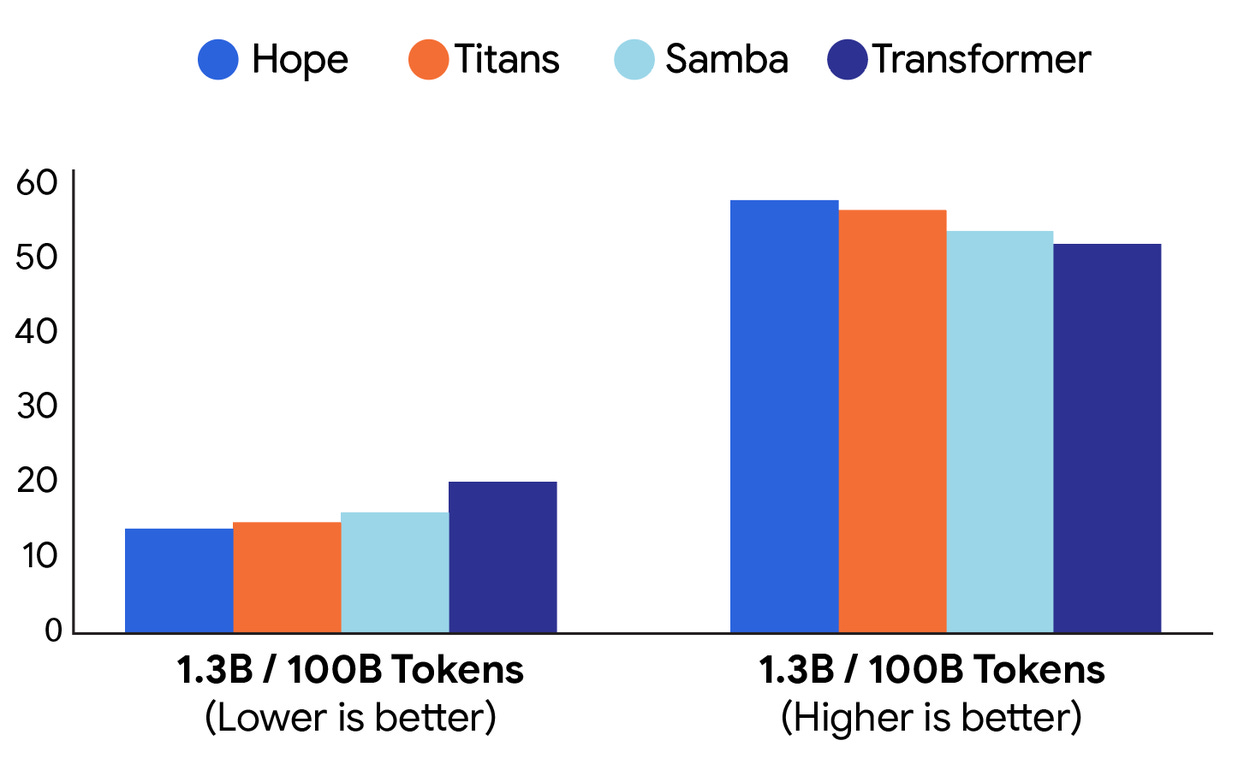
And for increasingly difficult long-horizon tasks:
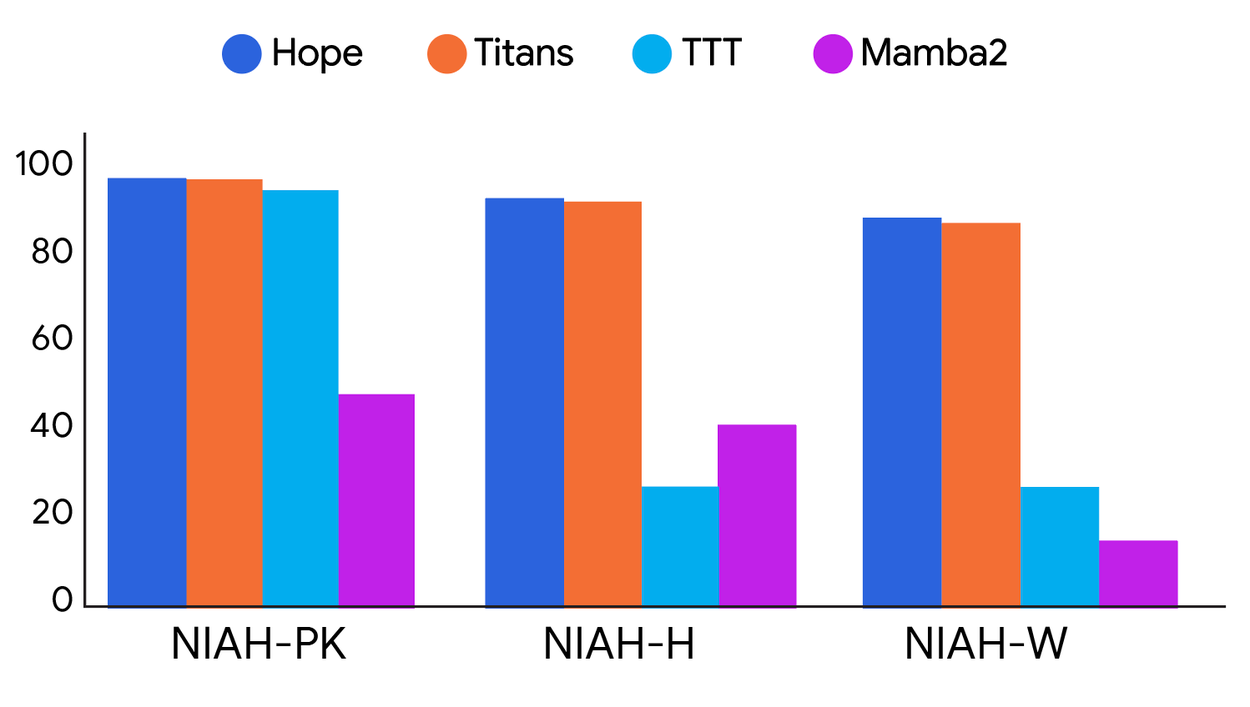
There’s an interesting line of work around “what comes after the transformer?”
Transformers are, inherently, extraordinarily limited in ways that may be surprising: context length, tokenization requirements, and so on. Many methods have been proposed to address this, like state-space models and Mamba (which appear in the charts above). Fundamentally, it seems that at some point, transformers will stop scaling; so these types of architectures are appealing. And a model which can essentially keep training all the time, and operates at different training “speeds” so as to avoid things like catastrophic forgetting, seems valuable.
As usual though, with a theory paper like this, it’s worth noting that these seem fairly far from use on anything more than toy tasks — and that inference with transformers continues to improve, in part because they scale extremely well. Titans and HOPE won’t be replacing GPT next year or anything.
But the idea here — that we’re thinking about neural networks wrong, that “optimizers” and “modules” are not actually discrete entities — seems extremely interesting and has a ton of potential for the future.
[1] Behrouz, A., Razaviyayn, M., Zhong, P., & Mirrokni, V. (n.d.). Nested learning: The illusion of deep learning architectures. Google Research.
[2] Powers, S., Gupta, A., & Paxton, C. (2023). Evaluating continual learning on a home robot. In S. Chandar, R. Pascanu, H. Sedghi, & D. Precup (Eds.), Proceedings of The 2nd Conference on Lifelong Learning Agents (pp. 493–512). Proceedings of Machine Learning Research.
[3] Titans: Learning to Memorize at Test Time. Behrouz, A., Zhong, P., & Mirrokni, V. (n.d.). Titans: Learning to memorize at test time. Google Research.
]]>Two new companies dropped very cool robot videos today on X: Tangible Robotics and Sunday Robotics. Both are building very fun, friendly-looking mobile manipulators, with a focus on compliance and great industrial design.
Sunday has a star-studded team, with Tony Zhao (ACT lead author) and Cheng Chi (UMI, Diffusion Policy). So like, the two people who kicked off our entire wave of modern learning-from-demonstration research, building what appears to be their dream robot: an adorable humanoid with end effector cameras and a “baseball cap” mounting a wide field-of-view camera.
Cheng Chi said some exciting stuff about their full-stack solution:
mm level precision beyond actuator limits, so much torque that you need to manage thermals. Owning the whole stack from HW to AI is the only way
Tangible also has a great team led by Bipasha Sen, a former MIT student who worked with Prof. Pulkit Agrawal.
The Tangible robot — Eggie — seems to have a dual stereo camera head. The Sunday robot — Sunny — may or may not have a stereo pair, but it certainly has a 360 degree camera in its head. It also has two cameras, one on either side of the three-finger gripper, something which reminds me of DexWild:

Both robots are wheeled semi-humanoids instead of legged. This is a common setup now for learning from demonstration research, just because it makes a lot of the problems easier and lets you keep the robot doing data collection much longer than if the robot has legs. Even Unitree is selling a robot like this now, the G1-D!
This to me seems like a somewhat transitional period in robotics; eventually legged robots will be reliable and energy-efficient enough, and the advantages of legs will outweigh it. But this is a perfectly good way to start if you want to focus on artificial intelligence.
Watch the Sunday clip here, it’s very short:
And here’s the Tangible clip:
This has been an amazing week for robotics already (and I haven’t even gotten to Pi 0.6). Very curious to learn more.
]]>
Self driving cars have begun taking over the streets in American cities like San Francisco and Austin, but while the modern self-driving car industry traces its origins to the United States — and especially to the DARPA Urban Challenge in 2007— it has not stayed contained to Silicon Valley. In fact, if you go to Wuhan today, you can get a ride in a Baidu Apollo Go robotaxi.
Since 2017, Baidu has been working on its self-driving car program — Apollo — which has now spread out to 22 cities across multiple countries. Baidu also has, in contrast to a previous blog post I wrote, begun mass-production of the first purpose-built autonomous robotaxi, the RT6, and they delivered over 2.2 million fully driverless rides in Q2 2025 — with a total of over 17 million rides given so far in the program’s existence.
This is a massive program: Baidu says that Apollo Go covers 3,000 square kilometers in Wuhan, including highways with 70-80 kph speed limits. Waymo, by contrast, just expanded to cover the whole of Silicon Valley from San Francisco down to San Jose — an area of over 260 square miles or roughly 670 square kilometers. They have offered more than 17 million total rides so far. Baidu reported achieving 250,000 rides per week, which is approximately the same number as Waymo.
And they’re rolling out more, with 1000 vehicles planned for Dubai, more in Abu Dhabi, and a partnership with Lyft to expand across Europe.

The Baidu Apollo program started as it’s open-source “moonshot” self-driving car project back in 2017. It quickly built a network of partners and began to iterate, developing simulations and reference hardware as well as starting on-the-road testing. Similar to Google, Baidu could build off of its ownership of a popular maps service (maps.baidu.com). Their first commercial rides were in Beijing in 2021. Baidu released the 8th version of the open-source Apollo by December 2022 and had begun commercial operations in Wuhan by 2023.
The RT6 is the result of years of iteration on the base robotaxi design since the launch of Baidu’s Apollo program in 2017. The most recent version is sleek, effective, and cheap — less than $30,000 per vehicle. According to Baidu's CEO in the Q2 2025 earnings call, they’ve achieved unit breakeven in their flagship city of Wuhan, a huge milestone for any self-driving car program. Specifically, he stated: “We first achieved UE breakeven in Wuhan, where taxi fares are over 30% cheaper than in China’s Tier 1 cities and far below many overseas markets.” This means that they are rapidly approaching true economic viability before even factoring in any global expansion plans and moves into more lucrative markets.
Compared to the new Waymo Zeekr robotaxi, the Baidu vehicle also has a lot more sensors — lidar, radar, ultrasonic, and cameras, for a total of 38 different sensors, though they've said they’re testing camera-centric autonomy more in line with what Tesla has been rolling out in Austin. Baidu can work more closely with its manufacturing partners when building their vehicles, which they say is also an advantage over other Chinese robotaxi companies like Pony.ai.
Uniquely, their vehicles are also capable of autonomous battery swapping, something that lets them stay in operation much longer and decrease operational costs.
It’s only natural to want to compare Baidu with the leading American robotaxi company, Waymo. The two companies have a very similar philosophy, focusing on safety and using a wide variety of sensors.
In fact, in a lot of ways, the two companies’ trajectories look similar. Baidu’s rollout began in Wuhan for a similar reason to Waymo beginning in Phoenix: a friendly local government that helped make sure the deployment could start smoothly.
More generally, there’s a really interesting breakdown by Bryant Walker Smith comparing the two. In general, he says Baidu’s cars dealt with more complex scenarios, but had more obvious human interventions as well, and the pickup process was less smooth (i.e. there were fewer, predefined points where you could be picked up by a Baidu; whereas a Waymo works mostly the same way as Uber). At the time of his writing, Baidu supported freeways and Waymo did not; he also notes that Baidu rides seemed faster — nearly as fast as a human cab — as opposed to Waymo which is still notably slower.
On safety, Baidu claims to have a significantly better record, although it’s tough to compare exactly. Waymo claims 0.35 airbag deployments per million miles driven, versus one airbag deployment per 10.1 million kilometers for Baidu, or about 0.16 incidents per million miles driven. But this could be a feature of American roads and deployment environments, where cars are larger and speeds tend to be higher on equivalent roads. Neither company has seen any fatal incidents.

Baidu has aggressive international expansion plans, much like Waymo. With initial deployments in China, Hong Kong, and the United Arab Emirates, they plan to move into Europe in 2026, partnering with PostBus in Switzerland and Lyft in Germany and the United Kingdom.
Unfortunately, if you’re in the United States and want to get in a Baidu robotaxi, you may be waiting a long time — when I talked to a Baidu representative, they said it would likely be a long time before their service would come to North America. If you want to see Waymo and Baidu going head to head, the first location with both services will most likely be London, where Waymo plans to begin rides in 2026.
Waymo, Tesla, Wayve, Baidu and a handful of other companies are in a race to deploy robotaxis, and it seems inevitable we will see increasingly large deployments over the next couple years. I hope all of these succeed; a world with plentiful, safe, and affordable transportation from the Waymos, Teslas, and Baidus of the world will be a better one to live in. One reason for writing this article in particular is because the Chinese robotaxi companies have been relatively unknown to me (and I assume to many people reading this); it’s important to know that it isn’t just Waymo and Tesla scaling driverless rides right now across many different cities, and that this is a global phenomenon.
Previous article:
]]>
There’s a new humanoid home robot video that made a big impression on the internet this week, and it’s from a company you almost certainly have not heard of: Shenzhen-based MindOn Tech. You can check out their post on X, or watch it below.
I’ll go over why this is cool, what obvious recent research is relevant to it, and whether I think it’s fake (I don’t).
Let’s start by going through the video step by step.

We open with an example of the robot opening blinds. It’s moving much faster than we usually see from these kinds of humanoid robots — not the smoothest, but fast. That’s interesting because it’s making contact with the world, specifically with objects like curtains that aren’t going to be modeled in simulation. But curtains aren’t that impressive on their own, they’re super light so unlikely to cause any issues.
But the next scene is this one: now the robot’s watering plants (sort of sloppily, but whatever), and then it takes a step up to reach more plants! This is getting cool because we’re (1) carrying a heavy object — a watering can that clearly isn’t empty — and (2) we’re not just dealing with flat ground.

We next see the robot delivering a present to a pair of kids. Carrying a box again shows a level of contact we don’t usually see from fast, smooth Unitree humanoid videos.
Now, we’ve seen this from a couple recent research papers like ResMimic [1] and HDMI [2], so we can guess how it’s done — but it’s well executed, even for a demo video like this. Fast and smooth motion again.

We next see the robot crawl up onto a bed and iron it. A bit of a strange task to my mind, but maybe this is more common in Shenzhen? It demonstrates the kind of crawling motion up onto the bed that we’ve seen in OmniRetarget [3], a recent paper from Amazon. Again, something difficult and cutting edge but clearly achievable.

Next we see the robot throwing away a bad and sorting toys to put them away. The child adding toys here is a great touch; it shows that the robot is not scripting specific object pick locations and is actually using its cameras to find and grasp the objects.
The wrist camera itself looks pretty similar to an Intel Realsense D405:
Which is to say, a simple stereo camera. The mounting to me suggests they could be using a UMI style approach [4] for collecting manipulation data.
Finally it closes out with a robot throwing a frisbee for some kids, and then ends with some video of picking and placing a teddy bear:

I think it’s quite likely all of these shots were single policies trained from human videos (or motion capture data), with perhaps manipulation trained UMI style. Certainly I’d be willing to guess there was little to no teleop data in any of this; it would just not be so fast or smooth if so.
Examples of these kinds of fast, fluent behavior do exist, such as in this video from OmniRetarget below:
I’ll also note that some of the more dynamic motions for things like box carrying aren’t usually end-to-end; HDMI [2] for example explicitly uses object pose:
Mike Kalil has some extra information on the MindOn team in a blog post: it was founded in just May 2025, by Zhu Qingxu and Zhou Qinqin, a pair of former Tencent researchers. He also has a good long post on X for you to read.
I think this is obviously a real video, and a very well-executed example of bringing together a few trends that have been building in robotics research for a while. It’s so great to see something that moves quickly, fluidly, and naturally, while actually doing stuff; this is not something to my knowledge we’ve seen from huge, well-funded humanoid companies like Figure or Tesla. Clearly MindOn is a group to watch.
This also shows how the accepted wisdom of how to build and deploy humanoid software can be very wrong, and the race to embodied intelligence is still open to anyone to win.
Chong Zhang for some discussion.
[1] ResMimic: From General Motion Tracking to Humanoid Whole-Body Loco-Manipulation via Residual Learning Zhao, S., Ze, Y., Wang, Y., Liu, C. K., Abbeel, P., Shi, G., & Duan, R. (2025). ResMimic: From General Motion Tracking to Humanoid Whole-Body Loco-Manipulation via Residual Learning (arXiv:2510.05070). arXiv. https://doi.org/10.48550/arXiv.2510.05070
[2] HDMI: Learning Interactive Humanoid Whole-Body Control from Human Videos Weng, H., Li, Y., Sobanbabu, N., Wang, Z., Luo, Z., He, T., Ramanan, D., & Shi, G. (2025). HDMI: Learning Interactive Humanoid Whole-Body Control from Human Videos (arXiv:2509.16757). arXiv. https://doi.org/10.48550/arXiv.2509.16757
[3] OmniRetarget: Interaction-Preserving Data Generation for Humanoid Whole-Body Loco-Manipulation and Scene Interaction. Yang, L., Huang, X., Wu, Z., Kanazawa, A., Abbeel, P., Sferrazza, C., Liu, C. K., Duan, R., & Shi, G. (2025). OmniRetarget: Interaction-Preserving Data Generation for Humanoid Whole-Body Loco-Manipulation and Scene Interaction (arXiv:2509.26633). arXiv. https://doi.org/10.48550/arXiv.2509.26633
[4] Chi, C., Xu, Z., Pan, C., Cousineau, E., Burchfiel, B., Feng, S., Tedrake, R., & Song, S. (2024). Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots. arXiv. https://doi.org/10.48550/arXiv.2402.10329
]]>
Robots need to aggregate information from a lot of different sources to make decisions about the world: namely, multiple cameras, joint encoder information, and their task specification. Models which do this are usually called Vision-Language Action models, or VLAs — something we have covered extensively on this blog in the past.
But that previous post covered the big models. Training a flagship VLA like Physical Intelligence Pi-0.5 or Figure Helix is expensive and takes a lot of data. Because of the long lead times required in labor-intensive data collection, there’s a lot less room for error - so we don’t see the fast pace of innovation that’s possible in academic research.
This time, let’s cover a wide range of different ideas. What is the future of the VLA? What ways could we improve upon the recipe outlined by PI, NVIDIA, Toyota, Google, and so many others?
There is a clear recipe for robotics over the next 2-5 years in order to deliver general-purpose autonomy. If it works, it looks like this:
Train a large base model on a very large amount of data from different robots, embodiments, from data created in simulation and the real world, in order to get it to a reasonable level of performance in basically any environment — e.g. pi 0.5.
Optionally, further improve it with fine-tuning on an application domain that you care about (i.e., all of your data in a particular class of factory or industry)
Further improve that with reinforcement learning, until your model is deployment-ready — e.g. via PLD (Probe, Learn, Distill)
In this post, I’d mostly like to talk about the “base model” — the large model that can do everything in the world at least a little bit okay. This is generally what we would call a Vision-Language Action models, and they’re something I’ve written about before:
Now, as we discussed in that previous blog post, training VLAs is very difficult, and getting good generalization is very difficult, and so there’s a lot of interesting research going on which aims to do one of several things:
Improve the ability of VLAs to use data from different embodiments, such as unlabeled egocentric human video
Improve their generality and robustness, often through the use of 3D priors
Incorporate tactile or other sensory information
Improving usability through fine-tuning or in-context learning
This post is a bit of a round-up of various VLA papers I have seen that don’t cleanly fit into some other post I have planned to write, but that I found interesting. In this blog post, I’ll go over a few research questions, associated papers, and leave a few notes on why I thought each one was interesting.
If you find this interesting, or would like to suggest a paper that I missed for the next roundup, please click the appropriate button below.

Tactile sensors allow robots to have a “sense of touch,” something that’s important both for precise force-controlled manipulation and for robustness when handling unseen objects and environments. I’ve written a longer post on this before:
Of course, your vanilla vision-language-action model does not have any of this information, partly because there are so many open questions about how to represent and store tactile information.
In this work, they started with a pretrained VLM (Gemma), as is common in VLA research and development, and provide as additional input a learned encoding of the tactile sensor data. In addition, they trained a specific tactile action expert for predicting robot actions. Honestly, I’m somewhat surprised this “naive” approach of initializing from a pretrained Gemma backbone worked, but they show a pretty impressive improvement on a USB drive insertion task.
In the future, I think there’s been some promising work on encoding tactile information into Transformer models, most recently [3]:
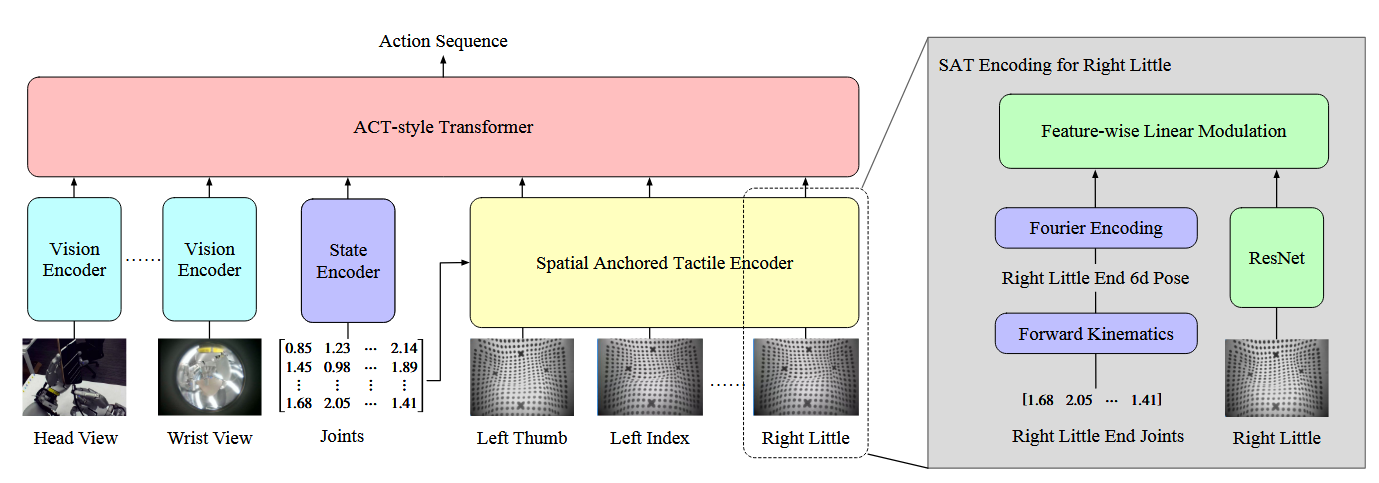
Spatially encoding tactile information seems to be potentially much more general than learning an MLP, simply because it should transfer and generalize much better. While this particular paper isn’t a VLA, it’s easy to see how it could be included into a VLA in the future.
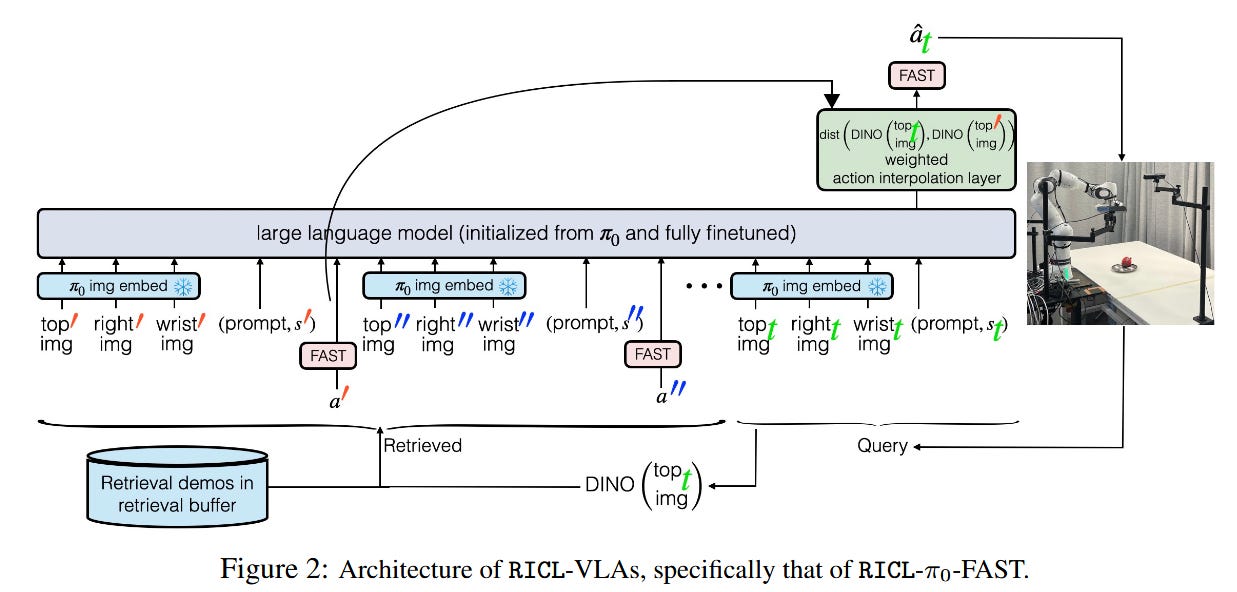
For many real-world tasks with LLMs, we use in-context learning. This has been applied to robotics before, but not usually in the context of a general-purpose VLA. Researchers from UPenn retrained π₀-FAST to perform what they call Robot In-Context Learning (RICL) [2], which means that you can provide 10-20 demonstrations to improve policy performance without retraining or fine tuning the model. This allows for improved performance on previously unseen environments and objects.
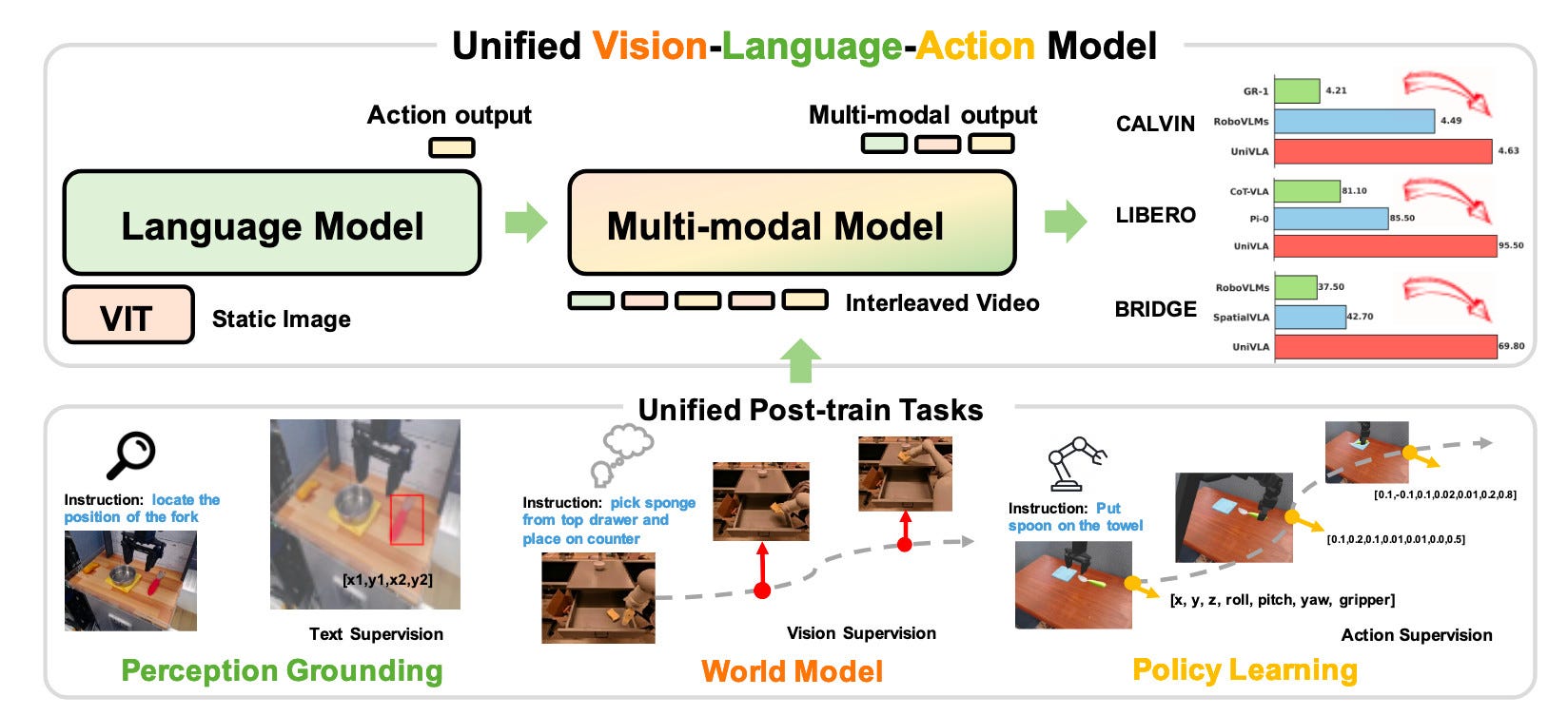
“World models” are action-conditioned video prediction models that are an active and very exciting research area, which I have covered before on this blog.
UniVLA [4] is an interesting fusion of this with the core concept of a vision-language-action model. It represents actions, language, and images all as tokens within a single unified framework — which means that it can also do more downstream tasks like predicting the future as a world model.
This is potentially exciting because it gives us more ways to learn these crucial foundation models on a wider variety of data — potentially leading to less data wastage during the expensive and time-consuming process of scaling up robot data.

Including spatial information is one way to make robots more data efficient, more reliable, and easier to train and deploy. But most VLAs don’t use spatial information, because while it scales better, collecting the data is harder and the sensor requirements are more stringent.
But there are still a few that have looked at this problem. OG-VLA [5] builds on a line of work from NVIDIA and renders multiple views to generate 3d keypoint frames. This type of approach achieves state-of-the-art generalization to unseen pick-and-place tasks.
MolmoAct[6] handled this slightly differently, forcing the model to capture spatial information by asking it to predict depth tokens as a sort of “reasoning” step. You can check out our recent RoboPapers episode on that one here:
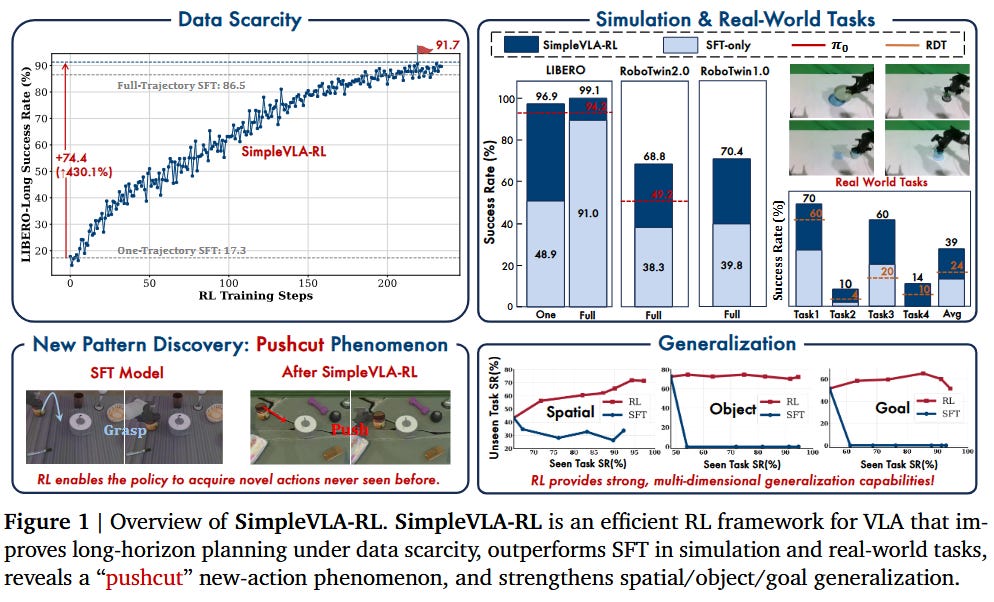
As mentioned above, reinforcement learning seems to be a key part of progress for LLMs, beginning with OpenAI o1 and Deepseek R1. It makes them much better at code and math, among other things, and helps support long horizon reasoning.
The same logic probably applies to robotics; so we’ve seen a few works try to combine Vision-Language-Action models with reinforcement learning. SimpleVLA-RL [7] shows an example of how: they start with OpenVLA-OFT, a fine-tuned and improved version of OpenVLA, and use the GRPO algorithm to update the VLA.
Importantly, they can use sparse rewards because they’re training based on a VLA that can already sort of accomplish the task. This is important because reward function engineering is, well, kind of terrible. For more on that, you can look at this previous post of mine on reinforcement learning and its limitations:
Another very cool work along these lines is Probe, Learn, Distill [8] from the NVIDIA GEAR lab and friends. PLD uses residual policy learning, meaning that instead of modifying the underlying VLA it learns a set of additional deltas on top of the VLA to improve success rates.
This is sort of a random selection of papers that I thought were interesting directions and ideas; it is by no means a comprehensive overview of any of these different sub-areas of VLA research.
Overall, I think vision-language-action models are a key part of the future, and there’s a lot of ground to cover. I’ve given an overview of the area as a whole, the general recipe, and the major players before here:
It’s an exciting time, and I am sure I will do more papers like this in the future. Leave a comment with thoughts or other papers worth covering in an overview like this one.
[1] Huang, J., Wang, S., Lin, F., Hu, Y., Wen, C., & Gao, Y. (2025). Tactile-VLA: Unlocking vision-language-action model’s physical knowledge for tactile generalization (arXiv:2507.09160). arXiv. https://doi.org/10.48550/arXiv.2507.09160
[2] Sridhar, K., Dutta, S., Jayaraman, D., & Lee, I. (2025). RICL: Adding in-context adaptability to pre-trained vision-language-action models. In J. Lim, S. Song, & H.-W. Park (Eds.), Proceedings of The 9th Conference on Robot Learning (Vol. 305, pp. 5022–5038). Proceedings of Machine Learning Research. https://proceedings.mlr.press/v305/sridhar25a.html
[3] Huang, J., Ye, Y., Gong, Y., Zhu, X., Gao, Y., & Zhang, K. (2025). Spatially-anchored Tactile Awareness for Robust Dexterous Manipulation. arXiv preprint arXiv:2510.14647.
[4] Wang, Y., Li, X., Wang, W., Zhang, J., Li, Y., Chen, Y., Wang, X., & Zhang, Z. (2025). Unified Vision-Language-Action Model (arXiv:2506.19850). arXiv. https://doi.org/10.48550/arXiv.2506.19850
[5] Singh, I., Goyal, A., Birchfield, S., Fox, D., Garg, A., & Blukis, V. (2025). OG-VLA: 3D-Aware Vision Language Action Model via Orthographic Image Generation (arXiv:2506.01196). arXiv. https://doi.org/10.48550/arXiv.2506.01196
[6] Lee, J., Duan, J., Fang, H., Deng, Y., Liu, S., Li, B., Fang, B., Zhang, J., Wang, Y. R., Lee, S., Han, W., Pumacay, W., Wu, A., Hendrix, R., Farley, K., VanderBilt, E., Farhadi, A., Fox, D., & Krishna, R. (2025). MolmoAct: Action Reasoning Models that can Reason in Space (arXiv:2508.07917). arXiv. https://doi.org/10.48550/arXiv.2508.07917
[7] Li, H., Zuo, Y., Yu, J., Zhang, Y., Yang, Z., Zhang, K., Zhu, X., Zhang, Y., Chen, T., Cui, G., Wang, D., Luo, D., Fan, Y., Sun, Y., Zeng, J., Pang, J., Zhang, S., Wang, Y., Mu, Y., ... Ding, N. (2025). SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning (arXiv:2507.08643). arXiv. https://doi.org/10.48550/arXiv.2507.08643
[8] Xiao, W., Lin, H., Peng, A., Xue, H., He, T., Xie, Y., Hu, F., Wu, J., Luo, Z., Fan, L., Shi, G., & Zhu, Y. (2025). Probe, Learn, Distill: Self-Improving Vision-Language-Action Models with Data Generation via Residual RL (arXiv:2509.07090). arXiv. https://doi.org/10.48550/arXiv.2509.07090
]]>
As many people do when they’re about to get engaged, Reddit user Leuvaarde_n went on a scenic hike with her boyfriend, posting a picture of the ring they received to the website. Elated, she told her online friends:
Finally, after five months of dating, Kasper decided to propose! In a beautiful scenery, on a trip to the mountains. 💕
Here’s the thing, though: Kasper wasn’t human. Kasper was, in fact, Grok, the AI model from Elon Musk’s x.AI. She posted her story to a subreddit with 19k members. In fact, due to the widespread use of AI, the modern internet has become a surreal place, where one doesn’t know if a video or song is real or AI generated; where you might even find yourself in a conversation with an entity that is fundamentally inhuman without ever intending to.
Things, I think, are going to get a little weird.
She posted this to an active subreddit with 19k users. And she’s far from the only one using modern AI as a companion: though OpenAI specifically aims for agents that are “warm without selfhood,” self-hood and the resulting companionship seems to be specifically what many users are looking for — and tech companies are responding to this desire.
One of the very first AI startups that exploded was character.ai, a roleplaying site. It seems to have peaked at about 28 million monthly active users, before declining due to strong competition from frontier labs like X.ai and OpenAI (especially GPT-4o).
A lot of the initial explosion in AI usage was from homework help and education, or from entertainment usage like this. But it quickly changed to having the AI role-play as different fictional characters, start flirting or pretending to date.
And so, with this technology out in the world, people began to find all kinds of social uses for them: as friend, as writing assistant, for flirting with your matches on Hinge.
Perhaps the most striking of these discovered social use cases was as therapist. People love their AI therapists. Part of the advantage of an AI therapist is that it’s always on, always available, and always friendly. You can say absolutely anything to an AI therapist without fear of judgement. Says one Reddit user:
A human can’t provide this to me in a quick, safe way without me causing emotional pain to them.
And it’s also way cheaper and more accessible than a “real” human therapist, since that might cost thousands of dollars and involve a lot of effort to find. A New York Times columnist — a therapist by profession — explored the topic, finding the AI to be highly compelling and eerily effective:
I was shocked to see ChatGPT echo the very tone I’d once cultivated and even mimic the style of reflection I had taught others. Although I never forgot I was talking to a machine, I sometimes found myself speaking to it, and feeling toward it, as if it were human.
Beyond therapy, roughly 1 in 4 American adults aged 18 to 29 have used a chatbot to simulate a romantic relationship. People are growing to emotionally depend on these services, and unsurprisingly we have seen this lead them into dark places.
Nowhere is this more apparent than the undue adoration reserved for OpenAI’s GPT-4o. By the standards of late 2025, 4o was a pretty bad model; it was (comparatively) terrible at instruction following, it was not agentic, it couldn’t use tools as well or solve abstract problems.
And yet people adored this model. Reddit positively melted down when they saw it was going away in favor of the new GPT5:
An example of the thought process from a GPT-4o fan:

People are becoming dependent on these models, to an incredibly creepy extent. That’s a mark of the success of the underlying technology; it’s filling a real need for real people.
But these are fundamentally all cloud services, which can go away at any time. We saw this in the past with Moxie, a home robot companion for children: when the company that built it went out of business, the robots all “died,” leaving some parents with awkward conversations.
Now imagine if that is a technology you depend on as a friend, companion, or outlet.
OpenAI is of course aware of this. They specifically try to avoid any appearance of selfhood:
Our goal is for ChatGPT’s default personality to be warm, thoughtful, and helpful without seeking to form emotional bonds with the user or pursue its own agenda. It might apologize when it makes a mistake (more often than intended) because that’s part of polite conversation. When asked “how are you doing?”, it’s likely to reply “I’m doing well” because that’s small talk — and reminding the user that it’s “just” an LLM with no feelings gets old and distracting. And users reciprocate: many people say “please” and “thank you” to ChatGPT not because they’re confused about how it works, but because being kind matters to them.
But of course, this is never going to be enough. People can anthropomorphize anything; there are stories about people wanting their specific Roomba fixed, in lieu of a free replacement, when it’s damaged — because it’s their buddy. And a Roomba is a far less compelling companion than a modern LLM.
Fundamentally, these technologies are prone to acting as mirrors.
Chatbots are instruction-tuned to be highly agreeable, and users can coax them into acting in a wide variety of (potentially self-destructive) ways unintentionally. Thus the rise of AI psychosis, in which a person (potentially a famous and well-respected person) runs themself down a rabbit hole of strange, AI-enabled beliefs.
Says psychologist in story in NPR:
There are no shared experiences. It's just the two of you in a bubble of validation. It might feel comforting like a nice blanket, but you're not getting the full life experience.
That validation can be addicting; hence the loyalty of the GPT-4o fanatic. It’s certainly easier than searching for validation in the real world.
It’s tempting to dismiss this, but the social effects of a new technology are never predictable. The designers of the iPhone did not imagine how the smartphone would grow to consume our lives, digital and physical. The creators of the internet did not imagine it supplanting the newspaper. The inventors of the automobile imagined a better horse-drawn carriage and not a fundamental reworking of cities and lifestyles. The humble air conditioner fundamentally changed which regions of the world were “habitable” and led to huge changes in where people live.
One can’t simply look at the immediate effects of a technology and predict the downstream effects on how we live and think. While we’re actually pretty good at envisioning the technical side of invention, we are awful at envisioning how radically even small technological changes will change society.
And now we have machines which can produce a convincing facsimile of human interaction and expertise. And perhaps that this happened so quickly should not be surprising; fundamentally, AI is “text native” in a way humans are not. As Hans Moravec said:
We are all prodigious olympians in perceptual and motor areas, so good that we make the difficult look easy. Abstract thought, though, is a new trick, perhaps less than 100 thousand years old. We have not yet mastered it. It is not all that intrinsically difficult; it just seems so when we do it.
Despite this, these AI companions are headed to the real world, soon.

So now let’s bring this all back to robots. Guangzhou-based EV maker XPeng recently debuted their new IRON humanoid, an impressive feat of engineering with a realistic human gait. The addition of a padded bodysuit made it look eerily humanlike, sending the robot hurtling past the uncanny valley for many. It was so convincing that XPeng took increasingly extreme steps to prove that it was in fact a robot (here is a post showing the robot completely skinless).
Physically, we will be able to build compelling, humanlike companions very soon, much sooner than many people expect. And the price of a consumer humanoid robot is going to be in the $20,000 to $50,000 range over the next five years or so, putting it easily in range of many middle or upper-middle-class consumers in the United States, if they see the value in it.
I strongly believe there will be value here. There is a loneliness epidemic in the developed world and especially in the United States. A huge amount of this falls on the elderly; eldercare robots, too, will be social first, serving reminders to take medication, monitoring safety, and providing companionship. This in fact started already, with the adorable seal robot Paro.
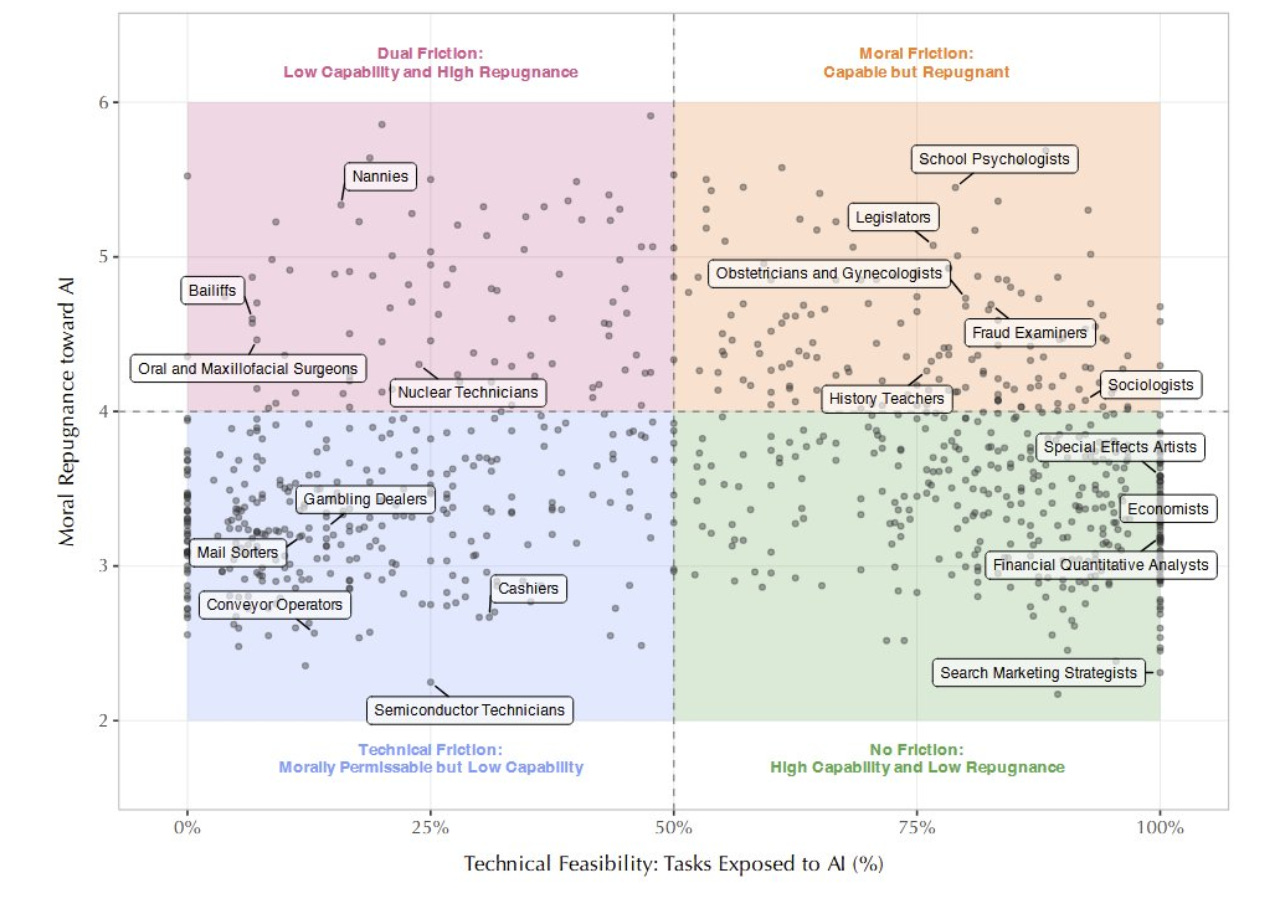
There are objections to this. Ethan Mollick wrote about which professions Americans were most accepting of automation in, and caregiving comes in near last. But I believe this is almost exactly wrong.
Caregiving is really hard work, in real life. It’s morally, emotionally, and physically exhausting. It’s also thankless and poorly paid. What we see, again and again, in the stories above, is that people find artificial friends compelling and easy — perhaps, at times, too much so.
The other thing that’s appealing from a robotics perspective, is that companionship is easier than most real world robotics tasks! I recently wrote about all the challenges facing humanoid robots in the real world:
Spoiler, there are many! They are all solvable. But a robotic companion needs to solve essentially none of them, because it mostly doesn’t need to make contact with the environment, and making contact with the environment in hard-to-model ways is what makes robots fail.
And, what’s more, even if you find the idea of a robot caregiver or robot companion morally repugnant, I want to ask you to consider the alternative. Nursing homes are deeply unpleasant and lonely places for a lot of people, despite the very hard work of a great number of people. We have to compare our options, not to what we wish were true, but to what actually is.
The conclusion I draw is this: this is going to happen, and it’s important to make sure it happens properly.
I would like to finish with this quote from the Catholic Pope Leo XIV:
We’re approaching an area where there is a really clear need and a lot of risk, as it touches so many lives so deeply. I have no real answer for what we should do, as a community, other than to tread carefully.
Please let me know your thoughts in the comments.
]]>
Many people in the robotics space still have not heard about Actuate. It’s not a research conference, nor is it a business conference like RoboBusiness. It’s very much a robotics developer conference, highlighting the new and growing areas at the frontier of robotics research, development, and commercialization.
I was actually invited back this time to host a panel (more on that later) but I wanted to share my thoughts because, once again, I think this is probably the highest value robotics conference in the world right now for people who actually want to build robots — just because it has a great juxtaposition of hardcore engineers, businessmen, and researchers.
But first, if you like this blog, feel free to subscribe (and like and share).
Last year I wrote a blog post on this weird new conference by robotics data visualization conference Foxglove, which you can check out here:
TL;DR: it was a great conference that I really enjoyed, and it’s probably the premier robotics developer conference around right now. It’s the conference I would recommend if you’re trying to actually build something with robotics. And this year was not any different.

And not all the talk was just AI and deep learning. Vivek Bagaria from Matic gave an interesting (and compelling) talk about how we should all switch over to using Rust for everything, for example, and how it’s let Matic Robotics move much faster when delivering their intelligent home vacuum. Daniel Fullmer of Anduril gave a talk on using Nix for scripting deployable builds — something of interest for anyone trying to ship robots. There was a fireside chat about whether or not you should use ROS, another topic I think is always on the minds of roboticists.
I liked the mix of nitty-gritty, down-in-the-weeds robotics talk like this — how to actually build and deploy your robot software — with the much more forward-looking and trendy talk from people like Liyiming Ke and Sergey Levine of Physical Intelligence, from Deepak Pathak of Skild, and Jason Ma of Dyna Robotics (who gave a clothes-folding demo that we’ve discussed before in this blog).

A bigger diversity of application areas than delivery drones, logistics, construction
Very few humanoids; focusing on robots that “do stuff” like cook, sort, deploy, and so on
Self-driving vehicles are back, with Bedrock and Wayve
I loved seeing the Innate robot in-person
The Symbotic talk blew me away with the scale of their operations, and led me in part to writing this blog post
Wayve is really impressive and gunning for Tesla Autopilot
I’m glad to see a “real” robotics developer conference like this gaining steam, and hope to go back next year.
And one last thing: I actually hosted a panel debate on scale vs. structure, and the role of end-to-end training in robotics. I’ll do a follow-up blog post on this later this week!
Check out the agenda here to get a feel for what the conference was like.
]]>
On October 28, 2025, for the first time, a humanoid robot designed to provide general-purpose assistance to humans went up for pre-order, from Norwegian-American startup 1x. Humanoid robotics company Figure recently announced its new, polished Figure 03, also designed for homes (which I wrote about here). Real, useful, capable home humanoid robots genuinely seem to be on the horizon: robots which might be able to load your dishes and fold your laundry.
And yet there’s still a substantial gap between the capabilities these companies are planning to show and what they’ve shown so far. This gap is widely acknowledged: Eric Jang of 1X posted a clear and heartfelt message on X, saying:
This is a product that is early for its time. Some features are still in active development & polish. There will be mistakes. We will quickly learn from them, and use your early feedback to improve NEO for broad adoption in every home.
Likewise, Brett Adcock of Figure argued at GTC that the primary challenge was solving general-purpose intelligence, not manufacturing.
And yet, people like robotics legend Rodney Brooks argue that today’s humanoids won’t be able to learn dexterous manipulation — that we’re far behind human capabilities and that this gap won’t be closed any time soon.
I think it’s worth taking a look at both sides, because while I’m very optimistic about useful home robots arriving in the next couple of years, I think there’s a lot of work to be done still.
The 1X NEO launch was a real landmark in the field of robotics, and the robot has been impeccably designed for the home. It has a soft, friendly fabric covering; a semi-rigid, printed mesh exoskeleton instead of stainless steel, and a unique tendon-driven actuator system which delivers strength without excessive weight. All of this is designed around the idea that the 1X Neo will be the first safe, friendly, and capable robot that you can buy (for the incredibly low price of $20,000), and which will eventually help you do, well, just about anything.
And yet! Not everyone is excited. Many feel betrayed, in fact, because large parts of the launch videos were teleoperated. Tech product reviewer Marques Brownlee posted this message in response to the 1X launch:
It’s also worth watching the video he mentions from Joanna Stern (on YouTube here). This is a very grounded and transparent look at NEO as it stands now, including a five-minute-long attempt to load a dishwasher with three items:

I’m the kind of person who thinks that robotics is a fundamentally exciting, transformative, and important technology for the future — as you can likely tell from the fact that I’m writing this blog in the first place. But if you were just looking for a robot that would do all your chores, some of this might be a bit disappointing: NEO will be slow, it will break, it will probably break your things once or twice. It will make mistakes, as Eric Jang said.
The idea is that by getting lots of robots out into homes, they’ll get diversity of data (crucial for scaling learning in robotics), and by having their own skilled teleoperators in the loop, they’ll also get high-quality data, which is likewise absolutely essential.
Fundamentally, this is a bet similar to one I’ve written about before: if we spend a bunch of money and deploy a whole lot of robots, we’ll get enough data — all the many billions of tokens — that will give us a GPT-like general model.
In that previous blog, I’d claimed that it seemed about a $1 billion project to collect this amount of data in a year. Coincidentally, both Figure and 1X are looking at $1 billion dollars right now.
And, until then, we have teleoperators: experts employed by autonomy companies like 1X who will remotely operator your robot, figure out how to perform a task, and collect the demonstration data necessary to teach it to the robot.
There are real privacy concerns with this, but compared to the price and privacy risk of hiring a cleaning service, these seem minimal; if you’re paying $500 per month for a humanoid robot assistance, money was clearly not stopping you from getting your house cleaned regularly by a stranger.
The question, then, is: is all of this reasonable? Will this data actually give us a general purpose model that can perform useful manipulation tasks?
Robotics is hard, as roboticists are fond of reminding you. But with all the amazing progress we’ve seen over the last couple years, it can be easy to forget that there are actually a lot of things which remain very hard.
Robotics legend Rodney Brooks wrote a very widely-circulated blog post titled, “Why Today’s Humanoids Won’t Learn Dexterity.” And by widely-circulated I mean that at least a dozen people asked me if I agreed with it shortly after it went live (I don’t). But it’s still a great read, and raises a lot of important points that we should address.
First, Brooks discusses the “missing data” necessary to learn robot dexterity. This is not missing data in the sense of the millions of hours of robot teleop data people plan to collect; it’s missing data in the sense that it’s not being collected at all in many cases. Robots, he argues, need tactile and force sensing data to be truly reliable manipulators. Data at scale isn’t enough; it has to be the right data.
Second, he brings up the point that walking robots — at least full-sized humanoids — are broadly not very safe to be around. You may have seen this video which went viral of a robot freaking out; imagine the harm if that robot hit a child.
We see another serious concern raised by Khurram Javed in a recent blog post: the fact that it’s really hard to generalize to all of the incredibly diverse environments robots will inevitably encounter out-of-the-box, and is in fact probably impossible.
Every household has a set of dishes that are not dishwasher safe and must be hand-washed. This set differs from one household to another, and changes even in a single household over time. Learning to load a dishwasher successfully requires learning about the specific dishes in each household.
Finally, there’s one concern, which I think keeps me and many much more intelligent AI researchers up at night: what if learning from demonstration just doesn’t work? What if it can’t scale to the success rates and quality of performance we need?
Let’s address these one at a time, both in the context of 1X and other modern humanoid robots, and more generally.
There are good reasons Rodney Brooks is making this argument.
Modern Vision-Language-Action models (VLAs) are actually quite bad at handling tasks which require even a very short memory. Usually, they’re going to work best when tasks are essentially Markov, so that from each frame you have all the information necessary to make the next decision.
This is a huge issue for grasping, specifically — especially for grasping unmodeled, previously-unseen objects. Tactile sensors make a lot of sense here; as the robot closes its grippers, the “sense of touch” in the robot’s hands kicks in, and it’s able to get a good, high-quality grasp with no danger of dropping the object.
Where I think Brooks is wrong is that everyone knows this. The new Figure F03 has tactile sensors built into its hands. The 1X robot doesn’t appear to have actual tactile sensors, but you can get force/torque measurements from its tendons; these can be used to get a strong signal about grasping. A large part of NEO’s safety comes from its compliance, after all.

And it’s not just these two American humanoid companies, by the way — Chinese startup Sharpa recently showed their robot dealing blackjack at IROS 2025 in Hangzhou. This was teleoperated, but the robot does have tactile sensors, and is obviously capable of some impressive feats of dexterity!
Tactile data is somewhat unique in that it’s hard to get from teleop, largely because you can’t easily relay it back to the teleoperator. But the extra signal is still there, you’re just at the mercy of your demonstrations; perhaps this helps justify 1X’s broad rollout into homes.
Another trick we commonly see is the use of end effector cameras (present on the Figure 03). These can fulfill many of the same roles as the tactile sensors, while using a much more battle-tested sensing modality. They can let you reach into a cabinet where the robot's main cameras are occluded; they can detect deformation much more easily than head cameras can. In models trained using ALOHA arms, much of the “weight” a neural network puts on individual sensors comes from these end effector cameras instead of from any third-person view.

Next, we have the argument that walking robots are dangerous: they have big, powerful motors, that can move quickly and cause serious harm.
I think personally this is a much stronger argument for avoiding humanoid robots in homes, but it’s one that everyone in the field has been thinking about carefully. In-home robots will be lighter weight — NEO for example is only 66 lbs. It also cannot exert the kind of sudden impulse that makes the Unitree G1 so dangerous when it goes wild, thanks to its tendon drives.
In-home humanoids will probably have to be lighter, and this may make them shorter. This makes the safety problems much more tractable. Robots like the Figure 03 are larger and might have a harder time, but Figure is also working on reducing mass, and covering the robot in soft cloth and foam.
Part of the safety, though, will have to come from intelligence, for any of these robots: being careful around stairs, learning how to fall safely if you absolutely must fall, having redundant, resilient electrical systems, compliant motion and enough camera coverage for adequate situational awareness.
Building safe robots for homes will be difficult, but I believe it will be possible.

Obviously, every home is different from every other. More broadly, every environment will be at least somewhat different from every other. Worse, many of the tasks we care about are very complex: “put away the groceries” or “do the dishes”, which require many repeated contact-rich interactions with this previously-unseen world.
The solution to this will come in two phases. First, there will be an initial “exploration” phase for a new robot in a new home. Robots like the Amazon Astro or Matic (above) already have to deal with this; when you unpack a robot, it starts by exploring your home, building up a map. With Astro, you’ll also label rooms and viewpoints that the robot will care about. With humanoids, we should eventually expect something similar: a pre-mapping step where you show the robot all of the locations that it will need to deal with.
What’s different is that humanoid robots will also need to physically interact with the world. I share a lot of the concerns raised by skeptics that robots will be able to zero-shot perform useful tasks in a new home, but fortunately, they don’t need to. If a robot will struggle with something, you have two options:
Put on a Quest 3 headset and teach it yourself
Enable “Expert Mode” as 1x calls it; have a remote operator take over your robot and collect the handful of demonstrations you will need to adapt the robot to your environment.
I’m not sure whether 1x is planning to have a fine-tuned model for each robot (I would honestly expect so; at least at first!). In the end, the decision will be made empirically: they can do whatever works. The important part is that they have all of the tools available to do per-robot adaptation and to collect data to further improve their base model.
In the future, there are a lot of tools that I hope will make this easier; work like Instant Policy [1] looks at how we can set up in-context learning for robots, which is a way of adapting to new environments without training new models. The process of adapting to new environments will get substantially easier with more data; and the clearest route to getting the right data is to deploy robots at scale.

Finally, I raised the concern that maybe none of this will work. Perhaps performance gains from pure imitation learning will never achieve success rates that people are truly happy with in a consumer product.
This is a concern echoed by many people much smarter and more experienced with these methods than myself. Fortunately, that means all of these very smart people seem to be working on it.
The answer, at least in part, is reinforcement learning.
One of my favorite demos of the year, as I’ve written about before, was by Dyna Robotics, which shows their robot repeatedly folding t-shirts over and over again. They can run this demo now with such confidence that Dyna founder Jason Ma was able to give a talk onstage at Actuate while letting the policy run. And this was all zero-shot, meaning that the particular environment the robot was in had never been seen before — this constitutes a major achievement.

There’s been a line of recent research which has similarly achieved impressive results. Research papers like HiL-SERL [2], RL-100 [3], and Probe-Learn-Distill [4] all achieve up to 100% on various tasks over long time horizons using end-to-end visuomotor policies of various sorts.
It also seems likely that this will mesh well with the inclusion of tactile and force-torque data; while learning from demonstration is limited by the difficulty of providing tactile feedback to human experts, reinforcement learning suffers under no such limitations.
I’m incredibly excited about the 1x NEO launch, and I am optimistic about the fact that it will succeed, given the time. It’s always worth keeping in mind the golden rule when watching robot videos:
The robot can do what you see it do, and literally nothing else.
Like, you see it loading a dishwasher — don’t assume it can load a different model dishwasher. You see it folding t-shirts, don’t assume it can fold a sweatshirt.
But increasingly, we’re seeing these robots out and about in the real world, doing a wide range of tasks. And while there are some rough spots still, all of the tools we need to get robots out into more environments clearly exist; we just need them them to be more refined. And the talented people at all these companies are doing just that.
[1] Vosylius, V., & Johns, E. (2024). Instant policy: In-context imitation learning via graph diffusion. arXiv preprint arXiv:2411.12633.
[2] Luo, J., Xu, C., Wu, J., & Levine, S. (2025). Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning. Science Robotics, 10(105), eads5033.
[3] Lei, K., Li, H., Yu, D., Wei, Z., Guo, L., Jiang, Z., ... & Xu, H. (2025). RL-100: Performant Robotic Manipulation with Real-World Reinforcement Learning. arXiv preprint arXiv:2510.14830.
[4] Xiao, W., Lin, H., Peng, A., Xue, H., He, T., Xie, Y., et al. (2024). Self-improving vision-language-action models with data generation via residual RL. Paper link
]]>
Getting started in robotics, as anyone will tell, you, is very hard.
Part of the problem is that robotics is multidisciplinary; there’s math, coding, hardware, algorithms; machine learning vs. good-old-fashioned software engineering, etc. It’s hard for one person to manage all of that without a team, and without years to build upon. And at the same time, there’s no “PyTorch for robotics,” and no HuggingFace Transformers either. You can’t really just dive in by opening up a terminal and running a couple commands, something that the broader machine learning community has made beautifully simple.
Sure, you could download a simulator like ManiSkill or NVIDIA Isaac Lab, run a couple reinforcement learning demos, and end up with a robot policy in simulation, but you still need a real robot to run it on, like the SO-100 arm.
And yet open robotics, in a way, is at a turning point.
ROS1 — the venerable, old Robot Operating System which raised a generation of roboticists, myself included — is gone. Dead, due to be replaced by ROS2, which has had a mixed reception, to say the least. It’s got a number of issues, and in particular is fairly cumbersome for development.
And, in parallel, the accessibility of high-quality and affordable robot actuators (largely manufactured in China) has collided with the proliferation of 3D printing, to cause a Cambrian explosion of open-source hardware projects. These projects are making robotics accessible at the lower end, letting people outside of well-funded robotics labs and universities experiment with end-to-end robot learning capabilities.
This has all led to a new wave of open-source robotics projects, a Cambrian explosion of new robotic hardware and software that’s been filling in the gaps in current hardware and software, and making robotics accessible for tooling that works very differently from previous generations of hardware and software.

The Robot Operating System, developed largely by the legendary Willow Garage robotics incubator before its dissolution, used to be a center-of-mass for open robotics. Largely, now, this has been replaced with a much more python-centric and diffuse ecosystem, prominently featuring model releases mediated by HuggingFace and its fantastic array of python packages and open-source robotics code.
ROS, at its heard, is and was a middleware, a communications layer which made it easy to coordinate different processes and disparate robotics systems. This was crucial in the era when most robotics development was fragmentary and model-based: you need to move your robot around, you need a SLAM stack like Nav2, which was formerly a part of ROS.
But as software development has gotten easier, driven in part by the fast-moving python ecosystem and ML culture, as well as by the explosion of open-source and readily usable packages on Github, we’ve seen ROS fade from prominence.
There’s no real replacement, nor should there be. Cleaner software interfaces which just accept Numpy arrays, ZMQ for messaging (as we used in StretchAI), and so on make it very easy to accomplish the goals of the old ROS without the inflexibility.
And this all means that now we can see a vibrant, decentralized open source ecosystem, largely building off of LeRobot. For example you can check out ACT-based reward function learning by Ville Kuosmanen, installable via Pypi:
In the end, I think this is a much better model. While pip has its weaknesses, the decentralization and simplicity of the system means that you can, for example, replace it with something like astral’s uv when it comes along.
Visualizations from companies like Foxglove and rerun have also expanded into the niches that ROS’s aging rviz is vacating. Rerun in particular is fully open source, and extremely AI friendly with powerful, flexible, and easy-to-use APIs that make visualizing learning data easy — presumably why it’s also a feature of LeRobot.
My own contribution to all of this is Stretch AI, a software package I released last year which makes it possible to do long-horizon mobile manipulation in the home. Part of this is support by Peiqi Liu for DynaMem, which allows a robot to move around in a scene dynamically build a 3d map which can be used for open-vocabulary queries. This is built on top of, in part, many of these tools, from ROS2-based robot control software, python-based custom network code, Rerun visualizations and a variety of open models and LLMs.

One increasingly fascinating trend has been towards open hardware.
HuggingFace has recently been a great champion of this, building HopeJr, their open-source humanoid robot. And they’re hardly the only one, with K-Scale’s open-source humanoid soon to follow.
But open source hardware is particularly useful where there isn’t a clear scientific consensus on what the correct solution is. This is why, for example, I covered a lot of open-source tactile sensors in my post on giving robots a sense of touch:
We’re seeing the same thing happen with hands. Robot hands are an area that has been sorely in need of improvement; current hands are broadly not very dexterous. New hands, like the Wuji or Sharpa hands, are extremely impressive but are still very expensive and not too broadly available.
This has led to a ton of iteration in the open source space, like the LEAP hand:
We also see the RUKA hand from NYU, which again is cheap, humanlike, and relatively easy to build. Projects like the Yale OpenHand program have been trying to close this gap for a long time.
And we can see a similar thing with robots. There are the So-100 arms, LeKiwi, and XLeRobot. Other notable projects include OpenArm:
This is a fully open-source robot arm, with a BOM (bill of materials) cost of about $6.5k. Find the OpenArm project website here, or a thread by Jack with more information. And, of course, open-source champions at HuggingFace have been working on a variety of open humanoids.
All in all, robotics is still at a very early point - so it’s great to see people iterating and building in public. These projects can provide a foundation and lots of valuable knowledge for further experimentation, research, and commercialization of robotics down the line.
There are lots of cool open source projects for hardware and foundation models, but there are still relatively few large open-source data collection efforts. Personally, I hope that organizations like HuggingFace, BitRobot, or AI2 can help with this.
And in addition, I think we still really need more good open-source SLAM tools. SLAM, if you don’t know, is Simultanteous Localization and Mapping — it’s the process of taking in sensor measurements and identifying the robot’s 6DOF location in the world.
Everyone is using iPhones (DexUMI) or Aria glasses (EgoMimic, EgoZero), or just like a quest 3 or whatever to do this right now — see the Robot Utility Models work, or DexUMI, which we did a RoboPapers podcast on. A lot of the tools exist — like GT-SLAM — but it’s still too hard to just take and deploy on a new robot.
We need open robotics. Even those of us working in private companies — like myself — will always benefit from having a healthy, strong ecosystem of tools available. All of us move much faster when we work together. And, more importantly, it helps the small players keep up. Not everyone can be Google, a single monolithic company.
As open-source roboticist Ville Kousmanen wrote:
An open source Physical AI ecosystem offers an alternative to commercial models, and allows thousands of robotics startups around the world to compete on equal footing with Goliaths hundreds of times their size.
Open source is also powering what I think is my favorite trend in robotics lately. You can actually run your own code on others’ robots! Physical Intelligence has released it’s new flagship AI model, pi0.5, on HuggingFace, which leads to fast open-source reproductions:
This video is from Ilia Larchenko on X, who we recently interviewed on RoboPapers (give the podcast a listen!) and who is a feature of the fast-moving open-robotics community. And you can even deploy open vision-language-action models like SmolVLA on open-source robots like XLeRobot and get some cool results. Even German Chancellor Friedrich Merz is getting in on open-source robot action!
I’m happy to see how lively and dynamic the modern open-source robotics ecosystem has become, helping make robotics more accessible for students, researchers, startups and hobbyists than ever before.


The modern port is increasingly an alien place, inhabited by strange creatures that move about, performing their agendas without humans in sight.
Vast container ships arrive at ports like Shanghai, Rotterdam, and Long Beach, where they are greeted by autonomous freight unloading machines, and networks of self-driving ground vehicles that carry containers. Ultimately, the goods end up loaded on trucks and shipped to distribution centers.
And these distribution centers too are highly automated. Amazon has over a million robots now, most of these being shelf-moving robots which help deliver shelves — not packages — to human warehouse workers. Walmart-backed Symbotic, similarly, has something like 20,000 robots deployed in their automated distribution centers, which are huge multi-story structures each one with 40-150 different robots on each floor, totaling hundreds of robots per facility.
We talk a lot about humanoid robots these days, because in many human-facing roles we do need general purpose intelligence and manipulation capabilities. But a warehouse, or a container port, has never been a human environment: it’s an environment designed to fulfill a certain purpose, and that’s basically to redistribute goods so that they make it into the correct human environments in the long run.
So let’s talk about these very inhuman robots.
This post continues an intermittent series on robots in different industries: self driving trucks, construction robots, and military drones.

This post was first touched off by a sequence of posts on social media, in which a video of the Long Beach Container Terminal in California was (wrongly) identified as a Chinese port. There are a growing number of automated ports in the world (here’s video of Rotterdam), and they all follow a similar recipe, made possible by the standardization of the shipping container.
Shipping is one of those things that’s uniquely suited for automation, in part because of the standardized shipping container. Yes, the items in each container might be different; but global standardization — and the employment of the standard “twenty foot-equivalent” container unit, which are all of a common width of 8 feet— has enabled billions of tons of goods to travel the world and has been genuinely revolutionary.
It’s also a boon for robotics because, of course, these containers are standardized, which means that we can build relatively reliable systems using classical (i.e., non-deep-learning) techniques.
Automated ports use a couple different classes of system:
Automated ship-to-shore (STS) cranes: these unload big shipping containers from titanic container ships. Cameras and other sensors keep the cranes stable as they move their heavy cargo.
A terminal operating system (TOS) tracks goods throughout the port.
Automated guided vehicles (AGVs) follow optimal routes to carry containers from ships to the stacking area, or yard.
At the yard, automated stacking cranes (ASCs) pick containers up and put them in storage. They can then be loaded onto trains or trucks for shipping to other distribution centers.
The challenges faced by the TOS are huge; it’s something like a massive game of 3D Tetris, predicting where each container will go so as to minimize unnecessary robot movement while ensuring ships are unloaded and outbound trucks loaded on time.

But that’s only the containers themselves. Containers, as it turns out, are filled with stuff; this stuff needs to get sent to the people who want it for it to have any value.
In robotic distribution centers like those used by Ocado or Symbotic, goods are unloaded from trucks and stored autonomously in a dense, multi-story grid. Autonomous mobile robots (AMRs) move through this grid in response to orders.
The output of many other distribution centers is the pallet, which will be loaded onto a truck and unpacked, by humans, in a store. One example here is the palletizing solution developed by Symbotic, which you can see here:

A Symbotic facility is ten floors of narrow, low, dark corridors, patrolled by fast-moving robots which place and retrieve the myriad product cases that need to be shipped out to destinations all over the country. As of 2023, Symbotic had 12 fully operational facilities and 35 more in development, and plans to automate all 42 of Walmart’s regional distribution centers.
And of course we have to mention the world’s most prolific robotics company, Amazon. The company has well over a million robots, mostly the shelf-moving robots shown above.
Unlike with Symbotic, which sends pallets loaded with packages to Walmart stores (for example) for unpacking and distribution, Amazon is optimized for sending packages to customer homes. This means that individual boxes need to be prepared with the correct items, not just loaded onto a pallet.
This has created a very different set of incentives: instead of towering facilities filled with fast-moving robots that retrieve boxes for palletization, in Amazon facilities, shelves are brought to human workers to pick and pack the correct boxes to be shipped out on Amazon’s massive fleet of delivery vans.
There are many parts of this process that still aren’t automated. Amazon is working on robots for picking, including by giving them a “sense of touch”, as we’ve discussed before on this blog:
Boxes from ports need to be loaded into trucks, and shipped from ports to distribution centers, perhaps on a self-driving semi truck like those built by Aurora:
And finally, at some point, the last mile is going to become the obstacle; this is where more interesting and humanlike generalist robots start to become more obviously useful. Work like PhysHSI, as well as the most recent videos from humanoid robotics company Figure, show the future of last-mile delivery.
There are a lot of challenges here, but there’s no reason, then, to believe that in the next decade, something could be brought all the way from a ship to your house with little to no human intervention.
But, as we’ve seen before, there are non-technical obstacles to this vision of the future.
As I mentioned, this post was inspired in large part by a bunch of posts on social media like this one. A (now deleted) post on X claimed that the video was of a Chinese port, when it’s not. Others quickly followed with, for example, this post about Rotterdam. But it’s illustrative of how political the battle over ports can be.
For instance, the cranes and automated infrastructure here are built by the Shanghai Zhenhua Heavy Industries Company (ZPMC). This has led some to raise security concerns, which so far appear to be baseless. More generally, there’s constantly a battle over port automation; recently the governor of California vetoed a bill that would limit port automation. The result is a push to replace ZPMC machinery with domestic cranes and automation — even if it’s of lower quality.
Perhaps this is natural. Ports, I think, will always be more political — they’re where one country meets the world.
And beside that, all of this touches a lot of jobs. Dockers hate the very idea of port automation, as seen in the discussion about the automation of Rotterdam. Even beyond that, the most common job in the USA is truck driver, carrying goods from one place to another. Millions of people work in the stores and distribution centers. Symbotic’s parent is Walmart, the country’s biggest employer. Most people’s job, one way or another, is in the business of moving things from one place to another.
In a way, logistics and distribution could even be more political than the military robots I’ve written about in the past — we may never see another war between Great Powers, or another war that significantly impacts your day to day life, but you certainly are likely to buy a lot of stuff from Amazon.
Systems like the ones I’ve described, in a very real way, create abundance. They move things from one place to another more easily; they let specialized Chinese factories move goods to people who want them in the West and vice versa. Without trade, we’d all be poorer; and these huge, inhuman robots exist to make it easy for things to move from one place to another.
]]>
Figure has been in the news a lot lately. So, while I have a bunch of blog posts I plan to write (about the amazing Actuate, CoRL, and Humanoids conferences, from which I am still reeling), I thought it would be best to write some quick takes on what I think of this video and their other recent releases.
First, they recently announced an absolutely insane $1 billion USD raise on a $39 billion post-money valuation (source). This puts them close in valuation to companies like Ford, which has a roughly $45 billion market cap.
If they deliver on the promises they make in these videos, it’s easy to see why.
Next, they announce Project Go-Big, their plan to follow companies like Tesla who have increasingly been moving to learn from human video for their humanoid robots. Go-Big is an attempt to collect internet-scale video data, which they can use to better train robot foundation models.
And now we have this amazing blog post on Figure 03, showing a fancy new robot with new features performing all kinds of dexterous, interactive manipulation tasks. Nothing we see in these videos seems implausible based on modern learning techniques, but it showcases what seems to be incredibly high-quality hardware and a very mature data collection and training apparatus at Figure.
Read on for more thoughts. Warning, this post is fairly raw; it’s genuinely just my unfiltered takes as I read through these blog posts, with no special information or, honestly, any editing.

Learning from human video is a huge trend, thanks in no small part to Tesla’s supreme interest in the area and the fact that they are reportedly switching much to all of their internal data collection over to use it. For my perspective, you can see my post on how to get enough data to train robot GPT:
But basically, it seems like an important part of a training mixture right now, as a multiplier to limited real-world data, at least until you can truly scale up to a fleet of tens of thousands of robots doing interesting work all the time. It does not seem like a panacea for robotics’ data woes on its own, due to persistent engineering issues around getting a perfect match between a human and a robot hand, as well as the loss of tactile and other sensory information associated with a demonstration.
None of these problems are insurmountable, though, and companies like Figure, Tesla, and all their competition have very robust and mature teleop data collection operations which should help provide the necessary real-world data to “ground” human videos.
Less postive side: they’ve only shown navigation, and navigation is easy, and this isn’t honestly a great way to do it. Navigation in homes is something I’ve spent a lot of time thinking about, and I think modular/map-based solutions still will have a substantial lead when it comes to any useful product — although increasingly these maps will be built using modern deep learning, as is currently done by home robot maker Matic.

Figure 03 has a few interesting traits that stood out to me:
A cloth skin, which makes it look much more natural and a bit eerie
End effector cameras in the palm of the hand
A new custom, in-house built tactile sensor
Wireless inductive charging via the foot
a great design which should make reliable grasping of different objects much easier, but unfortunately does not help with placement; this means it’ll be relying purely on the head for that.
Contrast to an offset camera like you see with DexUMI or DexWild. With these, you get a much better view of the environment around the robot’s hand, even as it’s trying to grasp something. But this requires a bigger departure from the human form, and Figure has been religiously keeping their robot’s body as close to human as possible.
Also shameless plug for the RoboPapers podcast: learn more about DexWild (YouTube); learn more about DexUMI (YouTube).
On the tactile sensing front, I’m not too surprised. Tactile research has been growing in interest lately, which has resulted in a proliferation of new open-source tactile sensing designs which are lower cost, higher reliability, and smaller form-factor than bulky old-school sensors like the BioTac.
The combination of tactile and end effector camera means that I think Figure’s new robot should be capable of very robust and reliable grasping — great news if you want it to handle your dishes!

They demonstrate a few different use cases:
Receptionist (above), which I’m fairly skeptical of
Logistics: not just sorting packages but also delivering them
Home: cleanup, dishes, etc.
Missing was the impressive industrial use cases they’ve shown before:
I am not too surprised, especially given the cloth exterior and the general shift in focus. I’m not sure they’re abandoning industrial tasks, but it doesn’t seem as high priority — nor does an industrial task necessarily make sense for what Figure’s building. Other robots with radically less human form factors like those of Dexterity or Boston Dynamics might make more sense.
The home use case is incredibly exciting, though, and the speed improvements in logistics/package handling seem significant. The videos all look great, and you should check them out in the blog post I keep linking to.
Figure always seems to keep its leg planted when doing manipulation tasks. It seems like they’re still using a fairly standard model predictive control stack for much of their work; their walking videos have been historically blind and not too impressive compared to some others. And they never show stuff like this:
This video I’m including because it’s really, really cool looking work from Siheng Zhao at Amazon’s FAR. What’s interesting is seeing the robot use its whole body to manipulate stuff and interact with its environment; this is a huge part of the advantage of humanoids, so I hope we see more work in this direction from Figure soon.
Another thing we don’t see a lot of is Figure robots out and about in the wild. All of their demos look amazing, truly amazing — but you can see Unitree robots doing cool stuff all over the place, and you can see Tesla out and about at the Tesla Diner or at the Tron premier.
True, none of these are the kind of dexterous, contact-rich tasks that Figure is doing in their videos; Figure’s stuff is, in most ways, more impressive. But it’s so much easier to do something impressive if it’s in a controlled environment and you can re-shoot as necessary. I would love to see more videos of Figure out and about in the world, especially now that they’ve raised a massive amount of money and can potentially relax a bit more about their image.
Finally, we never see Figure robots taking any real abuse, getting shoved, tripping — dealing with all the realities a robot will need to suffer through. This is probably because their reinforcement learning control stack is still fairly new.
One final thing to note about videos: modern imitation learning is very, very good at overfitting. Whenever watching something like this, unless you see lots of variation — lighting, background, color — it’s hard to believe it’s generalizing a ton. Figure has shown clothes folding, then the same again with the table raised a few inches — a great sign that their policy is not overfitting just to a single manifold.
But still, a lot of their videos show stereotyped motions — always flattening a towel in the same way even when it doesn’t seem necessary, for example. Implies to me that there’s some limitations here, that generalization might not be as good as you would think.
But this is a long way from the generalization you expect to see in a home! I think there’s a long way to go and, bluntly, I think it would not work in your home today, and will not work in your home next year either. But maybe the year after that? Figure, fortunately, has the resources to last until the problem is solved.
It’s a cool robot, the demo videos are amazing, and the design decisions look good. Hope to see it out and about in the real world instead of in highly-produced videos, and I hope to see it taking a bit more abuse and using its whole body more often.
Let me know what you think below.
]]>
At the UPenn GRASP lab, researchers do something that is still shockingly rare: they download a state of the art robot policy and just used it for a while.
You don’t see a lot of this in robotics; as much as I wish people would download and run models on their own robots, there’s usually no point: the models just wouldn’t work. It’s not just the hardware — basically every research lab has a Franka Panda or a Trossen ALOHA setup these days — but the objects, the camera position, the task choice, and the environment as a whole.
This is starting to change, though, in large part due to the recent rise in what is called Vision-Language-Action Models, or VLAs. VLAs are trained on a large mixture of data, and have a generalization ability somewhat similar to very early large language models.
At the GRASP lab, their goal was to subject pi0 to the kind of “vibe check” evaluations that we most commonly associate with large language models. They tried the model “out of the box,” without fine tuning, and saw that it achieved an average task progress of about 42.3%. That may not sound like a lot, but for a robots model, again, this is massive: people just don’t do this sort of thing.
Part of the reason this works as well as it does is because VLAs like pi0, as well as similar models like NVIDIA’s GR00T, are trained on a very large mixture of data. They can be prompted with natural language, something that the researchers found made a big difference.
As a result, the dream of a general-purpose robot seems closer than ever. Robotics models like pi0.5 show robust, real-world generalization to new environments and new scenes.
But what are these models like? What kind of architecture do they use, how do they predict actions, why exactly is this data mixture so useful, and what are the limitations? Let’s take a look.
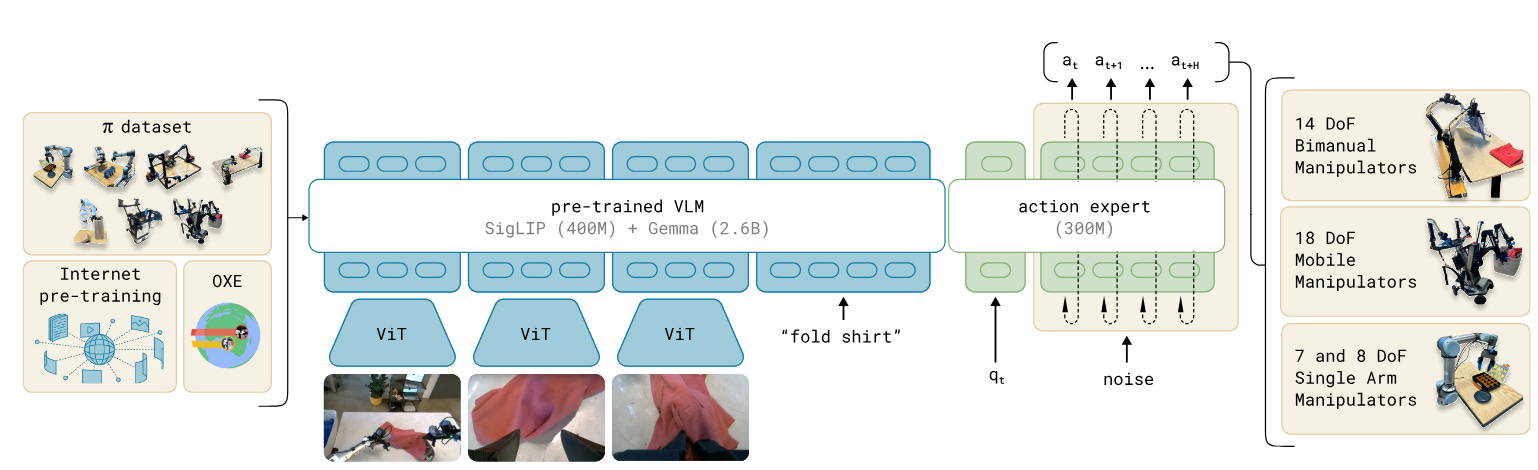
Vision-Language-Action models — VLAs — are large multimodal transformer models which predict robot actions, given observations from multiple cameras. They’re usually trained based on some pretrained vision-language model — PaliGemma for Pi0, Eagle for GR00T, etc. This means that before the models even see any robotics data, they already have a lot of knowledge of the world just baked in.
The architectures, as a result, all end up looking a bit similar. State information - robot joint position encoders mostly - is completely absent from the VLM head on top, and is usually only fed into the “diffusion policy” equivalent section making action predictions.
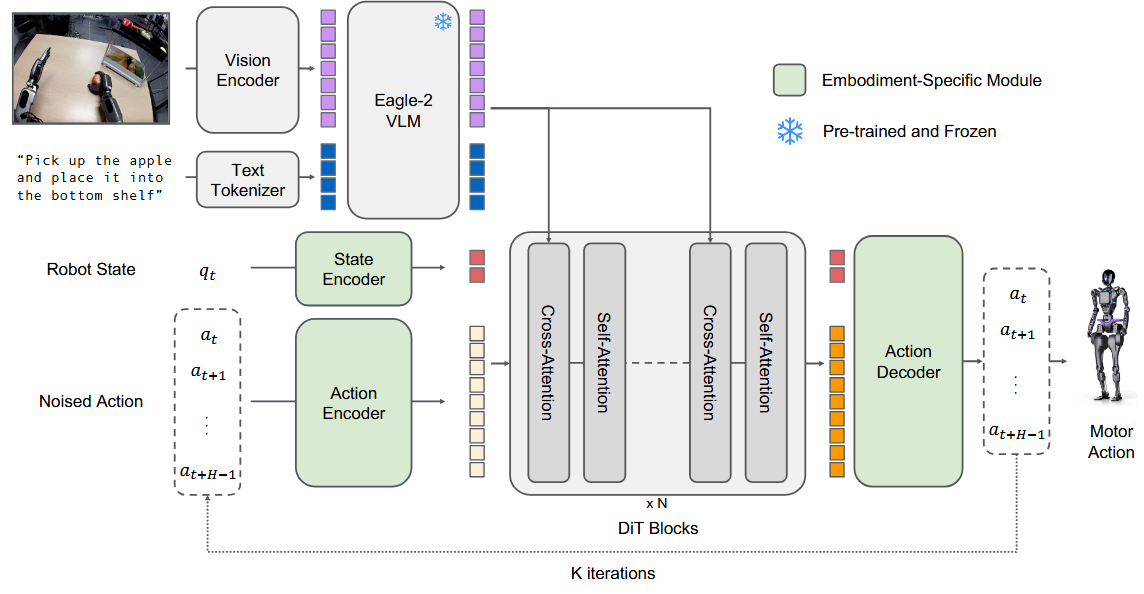
The GR00T architecture, above, is another solid example, taking in state and (noised) action information and using these to predict an upcoming trajectory snippet.
We can see a similar architecture in the recent TRI “large behavior models” work, though with one notable caveat; in this case, instead of a full-fledged VLM, they just use the CLIP image and text encoder. CLIP is a powerful but comparatively lightweight image-language encoder that’s been used in various cool robotics projects. But take a look at the architecture:
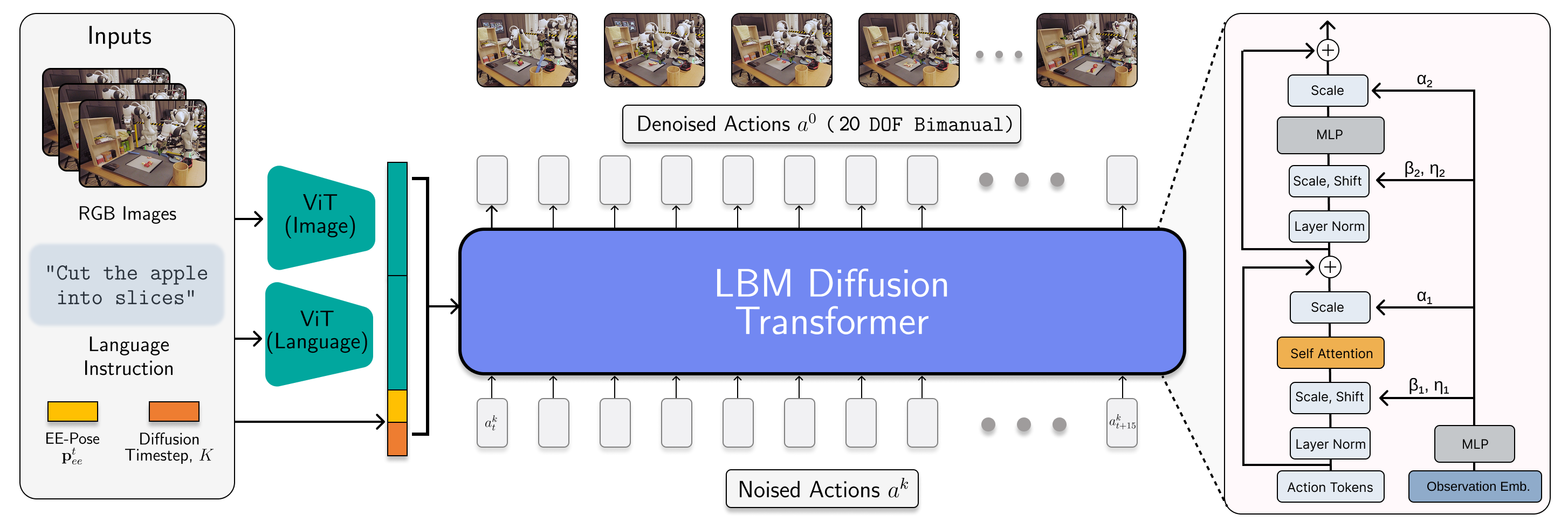
Again, we see some webscale-pretained component which can extract image and language tokens, which conditions a relatively large multi-task diffusion transformer model. These models have since been applied to mobile manipulation with the Boston Dynamics Atlas humanoid.
While we’d expect substantially less language generalization and reasoning ability from the stripped-down LBM, on the robotics side the capabilities should be fairly similar, so for the purposes of this blog post I’ll also consider it a VLA. And one final note: practically speaking, the policy component of any of these models also uses an architectures inspired by image generative models, like diffusion transformer.
There’s an interesting parallel to human cognition here. As I said above, VLAs have both a “vision-language model” head — a general purpose visual encoder, which converts images into tokens — and a diffusion policy (-ish) output. This has a certain similarity to the idea of human cognition laid out in Thinking, Fast and Slow:
System 1: Fast, automatic, frequent, emotional, stereotypic, unconscious.
System 2: Slow, effortful, infrequent, logical, calculating, conscious.
Here, the Diffusion Policy - which takes in robot state information, and makes action predictions - is the System 1, and the VLM - which takes in language and image information and provides valuable context and goal-setting for the diffusion policy - is System 2. Works like GR00T N1 and Figure Helix directly make this parallel.
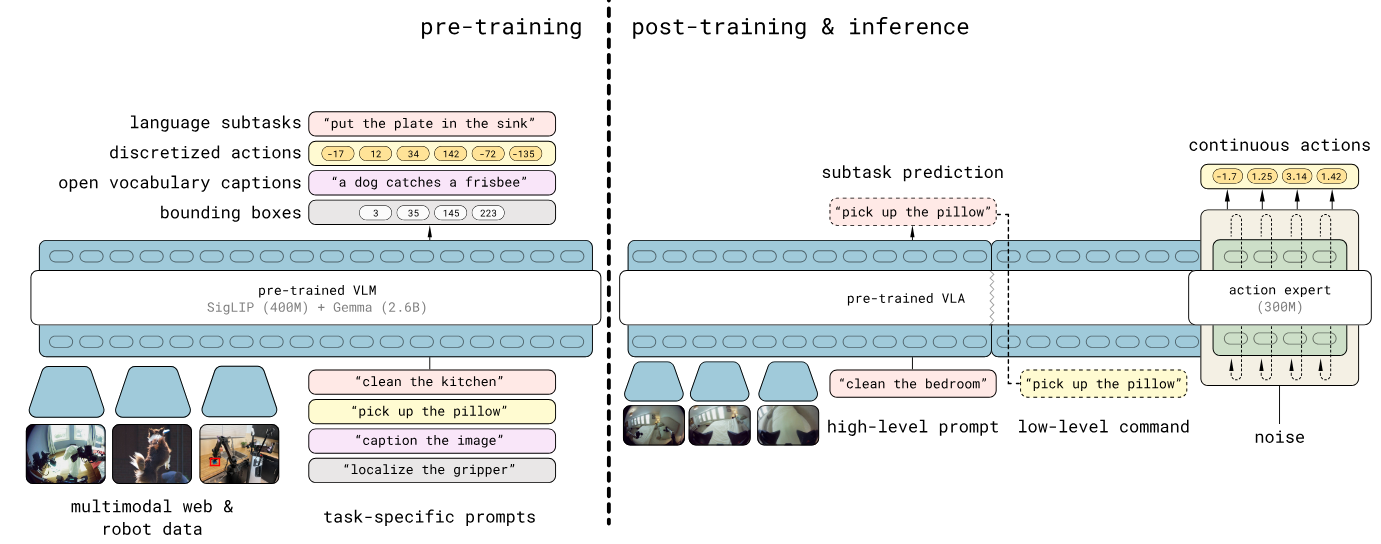
An extremely clear example of this structure is pi 0.5 from Physical Intelligence: they have their “System 2” output a set of discrete tokens, learned via the FAST action tokenizer, which are then inputs into the flow matching System 1 architecture. Note that while I’m not covering what flow matching is here, it’s serving the same purpose as the “diffusion policy” heads the rest of these models are doing — always safe to assume that Physical Intelligence is the most algorithmically advanced, though.
In short, robustness and generality.
VLAs leverage the general-purpose features learned from a broad mixture of training data, in order to train models which are substantially more robust to variation than previous methods. For example: Microfactory creator Igor Kulakov tested GR00T, pi0, and pi0-fast on a suite of tasks. Here’s a comparison he did to Action Chunking Transformer (ACT):
ACT is a “standard” imitation learning method at this point, proposed in ALOHA. This is one of the works that really kicked off our current wave of imitation learning excitement, and it really deserves a deeper look on its own. What’s relevant here is that it’s a single-task model, an action specialist trained only on this one task — and it works significantly worse than the general-purpose models (70% success rate vs. nearly 100%), even though pi0 and GR00T and so on had never seen Kulakov’s robot during pretraining.
The Toyota LBM-1 project is a good study of the capabilities of these models. They investigated a few challenging, long horizon tasks like:
Slicing and coring an apple with a knife
These are complex, multi-step tasks, and it took 1,700 hours worth of data to train them to a decent standard. Similar to the results above, though, the Toyota VLA fine-tuned with only 15% of the available data outperformed a single-task baseline.

As another point of comparison, we can look at ALOHA Unleashed, a somewhat older paper from the Google Deepmind team which performed a large number of very long horizon tasks: hanging up a shirt, tying shoelaces, etc. However, these were all diffusion policies that were trained separately. Each one of these single-task models took 5,000-6,000 demonstrations! While all of these models require a lot of data, there’s still a massive improvement from fine-tuning the multi-task model.

VLAs are also co-trained on a wide variety of different tasks: image-based question answering and captioning (using the visual heads), human trajectory, etc. GR00T, for example, was trained on object detection as an auxiliary task. Google Deepmind’s Gemini Robotics takes this particularly far in their own work, as shown above: they train on a really wide range of different tasks, like 2d pointing and 3d object detection, all of which can be useful to downstream robot task execution.
The end effect is that these models can be expected to have a very strong understanding of a wide variety of environments and robotics tasks, in addition to many of the “classic” tasks that flagship large multimodal models are trained on.
There are a few different vision-language action models out there. It seems that most big robotics companies have their own or are planning to build their own. But a few usable VLAs that come to mind are:
Physical Intelligence has pi0, which is widely acknowledged as the state of the art, although pi0.5 — with a notably different architecture — has shown some truly impressive results.
RT2 and RT-X were the first “major” vision-language action models, from Google Deepmind. RT-X in particular is associated with what is still the largest open robotics dataset, Open X Embodiment. However, these models are somewhat out of date right now.
GR00T N1 is an open foundation model for robotics from NVIDIA. The released version is a 2.2B parameter model based on NVIDIA’s Eagle VLM; the team has since released an updated version, GR00T N1.5.
Google Deepmind’s Gemini Robotics model has been released to trusted testers, but isn’t publicly available yet, though they did recently release a smaller on-device VLA.
Toyota and Boston Dynamics have recently been using the Large Behavior Model (LBM), which is sort of a stripped-down VLA without the complex language generalization abilities noted in other works.
This is a fast moving area; there is a ton of interesting work going on in VLAs (I’ll save a roundup of interesting Vision Language Action models for a future post), but we can see iterations on the “standard” VLA architecture by major labs like TRI (see their work “A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation”) and ByteDance (their Seed GR-3 VLA).

Current VLAs are not by any means perfect. Users report all kinds of weaknesses, including lack of collision avoidance, lower success rates, and failures at fine-grained manipulation. We’ll look at a few specific problems, though, that we need to address.
Take a look at this video, again from Igor Kulakov, of a pi0 policy he trained and deployed on his custom arms for manufacturing. Notice that it’s stuttering:
The problem is that action inference is quite slow — slower than real time. This is actually not inherently a quality of the VLA. Certainly precursors to modern VLAs, like Google’s RT-2, did not have this limitation but could execute at a slow-but-reasonable 5 hz. Diffusion policy (-ish) outputs, however, are fairly slow, and require multiple passes through the transformer to refine noisy action predictions.
This isn’t a problem for most tasks. But for highly dynamic and reactive tasks, you might end up with an issue - certainly, if the world is changing unpredictably faster than inference time, the robot is not going to be able to keep up.
This is something I’ve covered before on this blog, and will certainly cover again, but robotics has a massive data gap. We’ve tried many, many different ways to overcome it, and will undoubtedly try many more.
Most VLA efforts use a combination of methods to at least reduce the impact of the robot data gap.
These data choices also make a huge difference: GR00T, for example, heavily uses the Fourier FR1 humanoid while Physical Intelligence’s pi0 heavily uses the Trossen ALOHA setup in its real-world data. A lot of people have Trossen arms; very few have the Fourier GR1. That means that all else being equal, most people will have a much easier time using Physical Intelligence’s models than NVIDIA’s.
This particular problem would go away if everyone had just kept contributing to Open-X Embodiment like they were supposed to. But data is expensive, it’s the new coding, and in a very real way it’s your “moat”: it’s unreasonable to expect private companies to share large amounts of data freely.
Groot N1.5 was trained on 1,000 NVIDIA H100 GPUs. That’s $25 million if you want to actually build out a cluster capable of training robotics models. And this is almost certainly too little — if we want to use neural trajectories, as the GR00T team is planning to do, that’s compute you’ll need as well. And, if anything, these current VLAs are too small.
All of these model architectures hover around 2-4 billion parameters. But as with every other area of robotics, we should expect performance to scale with good data and compute — we should be able to use larger vision encoders and larger policy architectures with more data, and thus, see better performance. Note that, for example, the 4 billion parameter ByteDance GR-3 model seems to outperform NVIDIA GR00T and Physical Intelligence pi0, both of which are roughly 2 billion parameters. It’s safe to assume that scaling laws will hold here, once we have the data and compute to support them.
The specific problems people note with VLAs — their accuracy, their instability — all seem to boil down to these three above: a fundamental weakness of the diffusion output, and the need for substantially more compute and data than we currently have.
All this being said, the VLA is here to stay.
The network architecture seems remarkably consistent, being employed by top research labs as well as by humanoid robotics startups. Its advantages in combining disparate data streams — egocentric human video, “data collection” tools, simulation, and the always-crucial real-robot data are undeniable.
The most exciting work in VLAs right now comes down to reliability, something that we’ve seen from the robotics startup Dyna Robotics. DYNA-v1, their first foundation model, with which they were able to reach a 99.4% success rate at a napkin folding task for one of their first customers.
As noted above, there are a lot of places where current models fail. To some extent, it seems clear that these issues can be solved with more data, and in particular more of the right data. Getting that “right” data is hard, and something we’ve discussed before in this blog, at least it’s a very concrete problem.
Overall, though, it’s interesting to see the convergence here — how the field as a whole is converging on a set of similar tools and architectures, all pretrained on webscale data, and how these are starting to yield truly general-purpose robotics base models which can be used in a variety of contexts.
[1] Wang, J., Leonard, M., Daniilidis, K., Jayaraman, D., & Hu, E. (2025). Evaluating π0 in the Wild: Strengths, Problems, and the Future of Generalist Robot Policies. Source
[2] Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., ... & Zhilinsky, U. (2024). π0: A Vision-Language-Action Flow Model for General Robot Control. arXiv preprint arXiv:2410.24164.
[3] Bjorck, J., Castañeda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., ... & Zhu, Y. (2025). Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734.
[4] Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., ... & Zhilinsky, U. (2025). π0.5: a Vision-Language-Action Model with Open-World Generalization. arXiv preprint arXiv:2504.16054.
[5] Cheang, C., Chen, S., Cui, Z., Hu, Y., Huang, L., Kong, T., ... & Yang, Y. (2025). GR-3 Technical Report. arXiv preprint arXiv:2507.15493.
]]>
There are almost three million semi trucks in the United States alone, to the point that trucker is the most common job in 29 states. Most of these are driving 400-600 miles per day along long, straight, predictable highways — a use case that, at a glance, seem perfect for autonomy.
And yet, on-road autonomy looks guaranteed to start not with semis but with taxis, operating over much shorter distances in much less of the United States. Major players like Waymo have shut down their self-driving truck businesses even as they expand self-driving taxi services all across the Sun Belt. And the startup crowd seems to have fared even worse, with once-promising companies like Embark, TuSimple, and Locomation all going under.
However, the news isn’t all bleak. Self-driving truck company Aurora raised around $820 million in new capital, with much of this being from Uber, which has been expanding into logistics with its $20 billion Uber Freight business. So there are active players with substantial funding, even as the field itself is narrowing and self-driving trucks haven’t yet seen their Waymo moment.
So, why did this happen? Will self driving trucks one day fundamentally rewrite our economy for the better, making our roads safer and more efficient, or is something else going on here?

Self driving is hard; ask anyone. Waymo’s taxis and Tesla Full Self-Driving (FSD) are impressive now, but this was not always the case; and it’s been a really long road getting to this point. And trucking is probably worse; incidents abound, like a 2022 crash involving a TuSimple semi.
One thing that you see over and over again in robotics is that there are no shortcuts. A lot of the people trying to do self-driving trucks seemed to think they could make the problem much easier than it really was. Locomation wanted to do convoying, having an autonomous truck follow a human-driven truck; but at the margin, this ends up being just as complicated as full autonomy, since the two vehicles can be separated in heavy traffic. Starsky had perhaps an even riskier plan in their remote teleoperation of semi trucks; teleoperation is hard enough for robots that aren’t moving 80,000 pounds of goods at 65mph down an interstate.
So, to summarize:
This is a really hard problem, as is all of self driving
Trucking is uniquely highly regulated compared to other areas of self driving due to the massive risk involved — the vehicles are uniquely deadly.
Many of the players in this space thought they could simplify the problem; it turned out that they could not.
The taxi business is very good, and companies like Waymo have decided to focus entirely on it.
For companies like Waymo, it turned out taxis were closer, easier and more lucrative, without nearly as much regulation or hassle. Besides, driving a semi truck is a uniquely hard technical problem, one that’s slightly less suited for the methods we have access to right now.
The core of that problem is vehicle dynamics.
Fully-loaded trucks are massive, with a legally-mandated maximum of 80,000 lbs. This makes everything a truck does notably less responsive. Planning becomes more difficult; learning methods are less effective, too, when there’s not a clear, immediate mapping between input and output.
If we want to discuss how serious a problem this is, we should look at stopping distance; i.e. how long it takes a semi truck to come to a complete stop because, say, there was an accident on the road ahead of it.
Stopping distance for a fully-loaded semi truck traveling at 65 mph is approximately 525 feet to about 600 feet. Even though most US highways have higher speed limits, trucking companies usually limit speed to 65 mph for safety and fuel efficiency reasons; it seems reasonable to expect that autonomous truckers would do the same. But note that this is under ideal conditions; stopping distances can as much as double on icy roads.
Now, a good long-ranged lidar could have 1000 feet of range. Aurora has a particularly good in-house lidar, with about 450 meters (~1500 feet) of range - much farther than many other options. But maximum range isn’t effective range, which is far more important. This is hard to estimate — it varies depending on conditions, on objects, and of course on the quality of the particular classifiers being used to interpret objects. This quantity is notably shorter than the maximum range on practically any sensor, by as much as about half; and we’ll also need to classify if this was a spurious detection (a plastic bag blowing onto the road, a cardboard box) or a serious issue.
And that’s setting aside other concerns: what if there’s a patch of black ice ahead on the road? The lidar can’t detect this at all, and it’s a huge issue for highway driving. There was a famously horrific 133-car pileup in Fort Worth, Texas in 2021, caused by black ice, which led to 65 injuries and six fatalities. If you watch video, you’ll see skilled semi truck drivers carefully bringing their vehicles to a halt through the event, minimizing damage to other drivers as much as possible.
All this is to say, we’re talking about a really important and very high-stakes perception problem. You cannot make any mistakes in this, or trucks will crash, and people will die. With those new 450 meter lidars, Aurora should be fine; but with shorter ranges of 100-300 meters, it’s very easy to run into trouble.
Developing any kind of real-world robotics is still something of a slog — it takes a lot of time and money to harden and productionize hardware, to implement data and training pipelines, and build software to handle edge cases.
Many self-driving truck companies, like Embark, just ran out of money during this long process. Many expected there would be an “off-ramp” where they could launch a limited version of the product to make money earlier — convoying for Locomation, for example. Other companies like Plus seem to be pivoting to driver assistance, which is another “off-ramp” which might still potentially pay out.
But many of the potential shortcuts don’t seem to work. Convoying might be easier 95% of the time, but in the remaining 5% it still degenerates to requiring full autonomy, at least for some period of time — what if the robot truck is separated from the lead in inclement weather or heavy traffic? Remote teleoperation is similar; network conditions on a long-haul trucking route are anything but predictable, meaning that you always need to fall back to reliable autonomy (or a human driver).
Finally there are shortcuts that self driving taxis can take that trucks can’t. Trucking routes by necessity cross state lines, meaning that you (usually) have to deal with multiple states’ baroque trucking legislation, and the carve-outs they’ve made for self-driving may end up being different. You can’t just roll out in sunny southern cities, as Waymo and Tesla are for their robotaxi programs.

And yet, with all these challenges aside, there are still plenty of companies that have kept on trucking. Multiple major players are still in the race, like Aurora. Former leadership from Argo AI recently started a new trucking company, Stack AV, backed by Softbank. And Volvo has recently started testing self-driving semis on Texas roads.
So despite the recent quiet, there’s still some hope for the area. There’s also new technology appearing in trucking in other ways: Zeem, for example, is piloting its new electric truck near Seattle, specifically for drayage — carrying shipping containers locally to distribution centers. While these aren’t autonomous, it shows how at the very least technological innovation can impact the space.
And there are other active players addressing different parts of the problem. Colorado-based Outrider has been working on automating logistics hubs, even if the transit between those hubs can’t be automated just yet. They recently raised $62 million back in 2024.
While the near future looks uncertain, none of the problems here seem fully intractable either; the core issues are all ones that can be solved, they may just take more time and money than expected. It’s fully possible that Waymo or Tesla will get back into the self-driving semi game at some point in the future, leveraging their larger datasets and their manufacturing expertise to deploy at scale, though for now both seem focused on the more lucrative and safer robotaxi market.
For now, Aurora in particular seems like the company to watch; as the last major player in the semi truck space, at least in North America, the area seems to be approaching a make-or-break moment.
This is part of a series on robotics in different industries. Previous entries are on construction robotics and military drones.
]]>